
We are delighted to announce that our tools for Information Extraction from radiology reports are now available on GitHub and as a web demo online! Our language processing tools work on clinical text from brain radiology reports to extract information on stroke-related diseases. See a brief introduction to our online demo here.
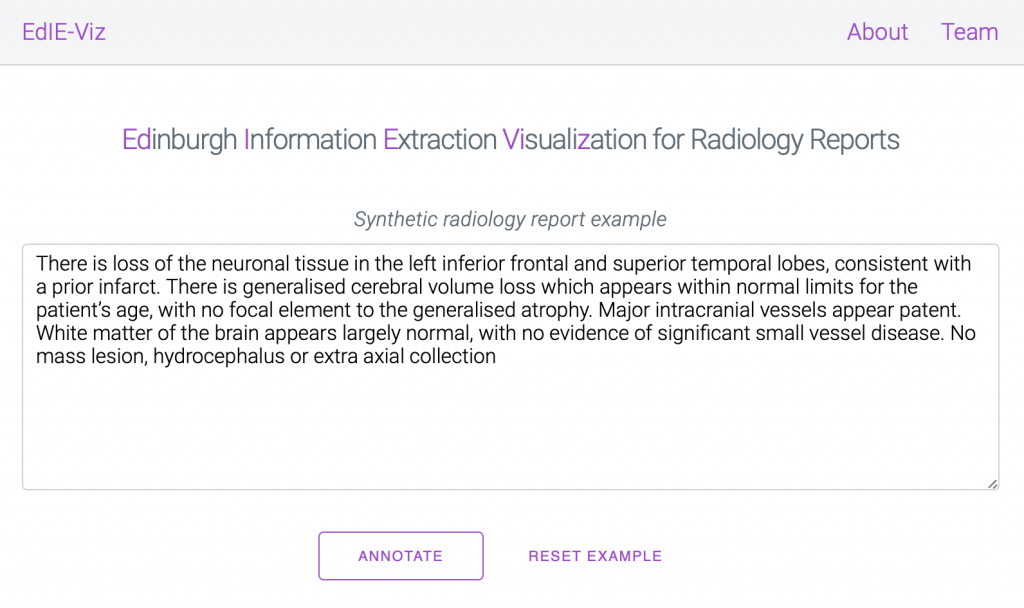
We release these tools in the hope that they will help speed up and improve clinical NLP research in this area by bringing the tools to the data, as in our experience assuming any form of patient data mobility is unrealistic.
We are very happy to collaborate with other researchers on clinical NLP projects, please get in touch for more information. Moreover, if you have any feedback or comments on our tools we would also be very happy to hear from you.
Our LOUHI 2020 workshop paper
The aforementioned tools accompany our workshop paper Not a cute stroke: Analysis of Rule- and Neural Network-based Information Extraction Systems for Brain Radiology Reports (Grivas et al., 2020) that we presented at LOUHI 2020. The recorded presentations will be available soon.
In the paper we discuss our insights from applying information extraction to brain radiology reports with the following three conclusions:
- The choice of metric matters and depends on your downstream task as caveated previously in this blog post by Chris Manning. Directly optimising models for F1 score (the harmonic mean of precision and recall) when doing named entity recognition (NER) has unintended consequences, such as preferring models that predict less entities. This can be seen when breaking down the F1 score into fine-grained error types.
- When relying on semi-automatic annotations, neural language models trained on large corpora can be used to check for any annotation inconsistencies and to get more insights on your annotated data.
- Applying negation detection learned by neural models to new external out-of-sample datasets leads to degrading performance and is still challenging, even in the large pre-trained language model era.
Questions from the audience
What is the reason for the rule-based system performing so well?
There is a lot of generalisable linguistic knowledge as well as medical expert knowledge incorporated in the rules that were developed by Claire Grover after discussions with medical experts. In addition, some mentions are generally straightforward to detect due to the specific vocabulary used. Moreover, the semi-automatic nature of the annotations also further contributes to the increase in scores.
Would you have any thoughts on metrics used for NER?
In the past, ACE and MUC have been used as more fuzzy metrics than the strict metric of the CONLL scorer, but the answer really depends on what our goal is. For hierarchical and fine-grained entity recognition, other metrics that take the hierarchy into account are likely more suitable, for example. Overall, we highlighted that it is beneficial and insightful to break down errors into semantically meaningful groups, especially when comparing models. David S. Batista has a great introduction and discussion of metrics used for NER.
Other papers and talks @LOUHI2020
LOUHI had a lot of interesting related talks, a selection of which we briefly summarise below:
- Hercules Dalianis presented his group’s work on de-identification strategies and their effect on downstream namee published in The Impact of De-identification on Downstream Named Entity Recognition in Clinical (Berg et al., 2020). This is important as decisions taken at the anonymisation stage of clinical text (which is not usually done by researchers) may lead to unforeseen effects at the NLP stage.
- Maciej Wiatrak presented a comparison of multi-task neural network architectures for entity linking published in Simple Hierarchical Multi-Task Neural End-To-End Entity Linking for Biomedical Text (Wiatrak and Iso-Sipila, 2020)
- Aditya Khandelwal‘s presentation was on negation and speculation cue and scope detection as multi-task learning published in Multitask Learning of Negation and Speculation using Transformers (Khandelwal and Britto, 2020).
- Florian Borchert presented work on their corpus of German clinical guidelines which includes structural metadata published in GGPONC: A Corpus of German Medical Text with Rich Metadata Based on Clinical Practice Guidelines (Borcher et al., 2020). This work is of interest to us since we work with clinical guidelines in English for a Clinical Guidelines Browser application.
- Minghao Zhu presented experiments classifying social media posts reflecting the personal experience of the poster published in Identifying Personal Experience Tweets of Medication Effects Using Pre-trained RoBERTa Language Model and Its Updating (Zhu et al., 2020)
- Guergana Savova, the keynote speaker, presented interesting summary of work in this field titled Clinical NLP, some tasks and applications in medicine and many points raised by her rang true to us.
Group thanks and funding
We thank our wider collaborators in the Edinburgh Clinical NLP Group for their help and feedback on this work. We are also very grateful for our funding that made this work possible: the MRC Mental Health Data Pathfinder Award (MRC – MCPC17209) the Alan Turing Institute fellowships and project (EPSRC grant EP/N510129/1), the MRC Clinician Scientist Award (G0902303) and the Scottish Senior Clinical Fellowship (CAF/17/01).
Andreas Grivas, Edinburgh, 18/12/2020