
an example 'timespan' annotation
|
|||||||||
| PREV PACKAGE NEXT PACKAGE | FRAMES NO FRAMES | ||||||||
See:
Description
| Class Summary | |
|---|---|
| Boundary | See design on paper for documentation :) Duplicates are identified as being boundaries with the same time stamp. |
| BoundaryAligner | Aligns two 'derived boundary annotations'. |
| BoundaryAlignment | A BoundaryAlignment keeps track of the alignment between the boundaries annotated by two different annotators (ann1 and ann2), and of the alignment between the two ('which boundaries are detected commonly?'). |
| BoundaryAlignmentToClassificationFactory | Given two aligned boundary lists, make two calc.Classification as follows:
1) All Pairs of aligned boundaries are Items; the Value for both annotators is True 2) For each unaligned boundary a Pair is made as Item with the unaligned boundary, and a null for the other annotator; the Values for this Item are True for the annotator who DID find a boundary, and False for the other. |
| BoundaryBasedInspection | Inspection tool for timeline segmentations (gapped or non gapped) that investigates whether two annotators identified the same segment boundaries. |
| BoundaryBasedInspection2 | Inspection tool for timeline segmentations (gapped or non gapped) that investigates whether two annotators identified same segment boundaries. |
| BoundaryExtractor | Given a lot of information about the NOM annotation layers in a NOMCorpus, extracts the derived 'boundary' annotation for a given annotator and returns it as a List of Boundaries. |
| DiscretizationBasedBoundaryToClassificationFactory | This class makes classifications from boundary lists by discretizing the timeline into items and using True or False as Value depending on whether the boundarylist contained a boundary in that segment. |
| DiscretizedTimelineInspection | Timeline Discretization |
| QuickScan | Inspection tool for timeline segmentations (gapped or non gapped) that does a quick scan of some general properties of the annotation. |
| SegmentAligner | Aligns two 'segment annotations'. |
| SegmentAlignment | A SegmentAlignment keeps track of the alignment between the segments annotated by two different annotators (ann1 and ann2), and of the alignment between the two ('which segments are detected commonly?'). |
| SegmentAlignmentToClassificationFactory | Given two aligned segment lists, make two calc.Classification where all Pairs of aligned segments are Items; and the Values are determined by the NOMElementToValueDelegate |
| SegmentBasedInspection | Inspection tool for timeline segmentations (gapped or non gapped) that investigates whether two annotators identified same segments. |
| SegmentExtractor | Given a lot of information about the NOM annotation layers in a NOMCorpus, extracts the 'segment' lists for a given annotator and returns it as a List. |
| TimelineDiscretizationClassificationFactory | This class makes classifications from an annotation by discretizing the timeline into items and assigning Values to each item based on the NomElementToValueDelegate applied to the annotation element with the largest time overlap with the item. |
Classes and programs to investigate annotations that are non-overlapping, possibly (but not necessarily) continuous, and potentially multi-label.
Note: before delving into this package, you probably want to read the documentation of the nite.datainspection package first, especially its introduction into the datainspection.data, datainspection.calc and datainspection.impl packages.
Note 2: This package is still being developed further.
A list of inspection tools and procedures in this package:
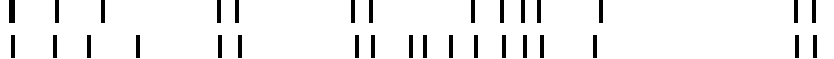
Boundaries extracted by the BoundaryExtractor for the two annotators. To interpret this in terms of 'whether the annotators identified the same boundaries', the relation between those derived boundary annotations must be analysed. The image below shows some relevant information. The red lines mark where two annotators found the same boundary, determined with a certain threshold 'th'; the blue dots mark boundaries found by only one annotator.

BoundaryBasedInspection explains this type of analysis in detail.
BoundaryBasedInspection and its supporting classes provide support for determining a sensible threshold for boundary alignment as well as for performing this alignment. In the end, the percentual agreement on the occurrence of boundaries gives an indication of how often annotators find the same boundaries, and the determined threshold value gives an indication of how precise the timing of the annotations is.

SegmentBasedInspection explains in detail how such inspection along these lines is supported by the packages, including an explanation how the calculation of kappa and alpha metrices is supported, and the automatic creation of confusion tables.
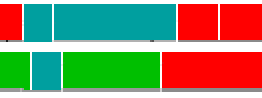
Some annotations do not lend themselves well for the event-like interpretation underlying the Segment alignment inspection.
[[EXAMPLE?]]
For such annotations we developed an analysis based on the amount of overlap for different labels. In the (hypothetical) example fragment below, we encounter from left to right the following agreements and disagreements: disagr(red, green), disagr(blue, green), agr(blue,blue), disagr(blue,green), disagr(blue,red), agr(red,red). Note the difference with the segment alingment based inspection. In the segment alignment inspection the first blue segment of the two annotators would be seen as "perfect agreement for identification and label, with some disagreement about timing". In the timeline discretization analysis the short overlap between green and blue at the beginning is counted as a label disagreement.
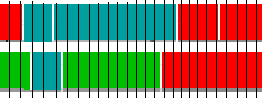
DiscretizedTimelineInspection explains in detail how such inspection along these lines is supported by the packages, including an explanation how the calculation of kappa and alpha metrices is supported, and the automatic creation of confusion tables. It also explains how varying 'th' has an impact on the outcome of the reliability measures.
|
|||||||||
| PREV PACKAGE NEXT PACKAGE | FRAMES NO FRAMES | ||||||||