 net.sourceforge.nite.datainspection.timespan.BoundaryBasedInspection
net.sourceforge.nite.datainspection.timespan.BoundaryBasedInspection
|
|||||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | ||||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | ||||||||
java.lang.Object
public class BoundaryBasedInspection
Inspection tool for timeline segmentations (gapped or non gapped) that investigates whether two annotators identified the same segment boundaries. Boundaries detected by two annotators are taken to be the same if they are at most a (configurable) threshold 'th' apart. Kappa and alpha are calculated by giving a pair of such aligned boundaries the label 'true' for both annotators, and giving unaligned boundaries the label 'true' for the annotator who detected the boundary and 'false' for the other.

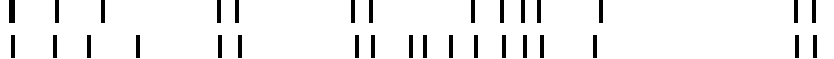
Boundaries extracted by the BoundaryExtractor for the two annotators. To interpret this in terms of 'whether the annotators identified the same boundaries', the relation between those derived boundary annotations must be analysed. The image below shows some relevant information. The red lines mark where two annotators found the same boundary; the blue dots mark boundaries found by only one annotator.

Aligned: 14
Unaligned A: 0 (100% aligned)
Unaligned B: 4 (78% aligned)
This information is reported by the class BoundaryBasedInspection.
Varying threshold 'th' gives information about the precision with which two annotators identified the same boundaries. Note however that 'th' should be low enough compared to the segment lengths in the annotations.
================
===Aligning f vs e
---
- th 0.0
50 aligned boundaries
For ann1: 15%.
For ann2: 18%.
---
- th 0.2
209 aligned boundaries
For ann1: 63%.
For ann2: 78%.
---
- th 0.4
228 aligned boundaries
For ann1: 69%.
For ann2: 85%.
---
- th 0.6
241 aligned boundaries
For ann1: 73%.
For ann2: 90%.
---
- th 0.8
243 aligned boundaries
For ann1: 74%.
For ann2: 91%.
---
- th 1.0
249 aligned boundaries
For ann1: 76%.
For ann2: 93%.
The list above gives an example output obtained from the BoundaryBasedInspection tool, for the FOA layer of the AMI corpus, with several variations of 'th'. For this specific annotation, 50% of the identified segments were shorter than 1 second. This means that the higher alignment percentages in the list are at least hard to interpret, and in the worst case not really meaningful.
To gain more insight in these numbers, one should therefore have a look at the visualisation of the boundary alignments for different values of 'th', to see whether the alignments make sense or not. Also, one should relate the range of 'th' that is tried out to the distribution of segment lengths in the annotation.
The following three images, obtained for the same AMI FOA annotation, show how setting 'th' too low will cause the alignment percentages to be unfairly low, and setting 'th' too high will lead to unfairly high alignment percentages. These images can be produced using the tool BoundaryBasedInspection.



In the end, if you have been able to determine a sensible value for 'th', this analysis can lead to an answer to the question "what percentage of boundaries have been found by both annotators?" (In this particular case, the answer should be "about 65% for annotator 1 and about 85% for annotator 2"). Furthermore, the range of values for 'th' for which an acceptable alignment is found gives information about the precision with which annotators have annotated the data. In this case, this seems to be somewhere between 0.2 and 0.4 seconds.
(Side remark. Note that this has an implication for your use of the data. If the precision is on a few tenths of seconds, you should not focus on learning frame-perfect automatic boundary recognition. Furthermore, your evaluation of your machine learning results should keep this margin when assessing whether a detected boundary is 'good'.)
TimespanItem) and Values are True or False (BooleanValue) depending on whether the given annotator has noted a boundary in that segment. These classifications can then be used to calculate CoincidenceMatrices and standard reliability measures such as kappa or alpha.
This is not a good idea!
The relative distributions of the labels true and false are extremely dependent on 'l': if 'l' gets smaller, the number of 'false' Values rises dramatically, whereas the number of 'true' Values is stable. This affects the outcome of the alpha and kappa values: they become higher when 'l' becomes smaller. On the other hand, smaller values for 'l' mean that less boundaries end up aligned (because a higher precision is required when 'l' is smaller), which means that kappa and alpha go down. And these two effects of course interact.
Conclusion: don't use that particular analysis (even though it was implemented in the class BoundaryBasedInspection2).
BoundaryBasedInspection and its supporting classes provide support for determining a sensible threshold for boundary alignment as well as for performing this alignment. In the end, the percentual agreement on the occurrence of boundaries gives an indication of how often annotators find the same boundaries, and the determined threshold value gives an indication of how precise the timing of the annotations is.
| Field Summary | |
|---|---|
java.lang.String |
agentName
the name of the agent for which you want to analyse the annotations. |
java.lang.String |
codingName
the name of the Coding in which the boundaries are to be found |
java.lang.String |
commonLayer
the name of the common layer shared by all annotators, can be null |
java.lang.String |
corpusName
corpus |
java.lang.String |
observationName
observation |
java.lang.String |
segmentElementName
the name of the Elements in the Layer in that Coding in which the boundaries are to be found |
java.lang.String |
segmentsLayer
the name of the Layer in that Coding in which the boundaries are to be found |
| Constructor Summary | |
|---|---|
BoundaryBasedInspection(java.lang.String c,
java.lang.String o,
java.lang.String codingName,
java.lang.String segmentsLayer,
java.lang.String segmentElementName,
java.lang.String agentName,
double thMin,
double thMax,
int thSteps)
|
|
BoundaryBasedInspection(java.lang.String c,
java.lang.String o,
java.lang.String codingName,
java.lang.String segmentsLayer,
java.lang.String commonLayer,
java.lang.String segmentElementName,
java.lang.String agentName,
double thMin,
double thMax,
int thSteps)
|
|
| Method Summary | |
|---|---|
void |
collectAlignments(double thMin,
double thMax,
int thSteps)
Collect for all threshold values the alignments for all annotator pairs, using the BoundaryAligner. |
void |
collectBoundaries()
Collect the derived Boundary annotations for all annotators. |
void |
collectClassifications()
Collect for all threshold values the derived classifications for all alignments, using the BoundaryAlignmentToClassificationFactory. |
void |
collectMatrices()
Collect for all Classification pairs the confusion and coincidence matrices used for calculation of reliability and inspection of confusions. |
void |
generateThresholdValues(double thMin,
double thMax,
int thSteps)
|
Clock |
getClock()
|
ClockFace |
getClockFace()
Returns the clockface of this class. |
NOMWriteCorpus |
getCorpus()
|
java.lang.String |
getCorpusName()
|
NiteMetaData |
getMetaData()
|
java.lang.String |
getObservationName()
|
void |
initReportPanel()
|
void |
renderBoundaries()
|
void |
renderRelations()
|
java.util.List |
search(java.lang.String query)
|
| Methods inherited from class java.lang.Object |
|---|
equals, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait |
| Field Detail |
|---|
public java.lang.String corpusName
public java.lang.String observationName
public java.lang.String codingName
public java.lang.String segmentsLayer
public java.lang.String commonLayer
public java.lang.String segmentElementName
public java.lang.String agentName
| Constructor Detail |
|---|
public BoundaryBasedInspection(java.lang.String c,
java.lang.String o,
java.lang.String codingName,
java.lang.String segmentsLayer,
java.lang.String commonLayer,
java.lang.String segmentElementName,
java.lang.String agentName,
double thMin,
double thMax,
int thSteps)
public BoundaryBasedInspection(java.lang.String c,
java.lang.String o,
java.lang.String codingName,
java.lang.String segmentsLayer,
java.lang.String segmentElementName,
java.lang.String agentName,
double thMin,
double thMax,
int thSteps)
| Method Detail |
|---|
public void collectBoundaries()
public void collectAlignments(double thMin,
double thMax,
int thSteps)
public void collectClassifications()
public void collectMatrices()
public void initReportPanel()
public void renderBoundaries()
public void renderRelations()
public java.lang.String getCorpusName()
public java.lang.String getObservationName()
public NOMWriteCorpus getCorpus()
public NiteMetaData getMetaData()
public Clock getClock()
public ClockFace getClockFace()
public void generateThresholdValues(double thMin,
double thMax,
int thSteps)
public java.util.List search(java.lang.String query)
|
|||||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | ||||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | ||||||||