The XML Library LT XML version 1.2
User documentation and reference guide
Language Technology Group
Chris Brew
David McKelvie
Richard Tobin
Henry Thompson
Andrei Mikheev
The XML Library LT XML
This document describes the XML Library (LT XML version 1.2), which consists of a set of C programs for manipulating XML files and a C application program interface (API) designed to ease the writing of C programs which manipulate XML documents. The LT XML API has changed slightly since the previous release (version 1.1).. LT XML now understands the structure of XML DTDs and can validate documents against them. Scores of bug-fixes have been made. But API changes have been kept to a minimum.
The documentation has two main sections. XML utility programs built using the LT XML API documents the user-callable utility programs provided in the LT XML system.
The other sections starts with an overview of the data structures (in Type reference) used to represent SGML structure in the API. Then follows the function reference, whose first section is Initialising LT XML.
This documentation is built using DocBook 3.0. We distribute SGML source (which you can read if you must), HTML, and RTF (mainly for printing).
Because the documentation is made with SGML, it will, it says here, be much easier to maintain in future.
Last update 17 February 2000
Comments and questions to: <H.Thompson@ed.ac.uk>
- Table of Contents
- I. User guide
- II. LT XML reference
- I. XML utility programs built using the LT XML API
- sggrep — works like the grep program in searching a file for regular string expressions. However, unlike grep , it is aware of the tree structure of XML files.
- sgmltrans — translate XML files into another format.
- sgrpg — systematically transform input document to changed output document
- sgcount — count elements in an XML file.
- knit — process compound documents using hyperlinks
- unknit — create hyperlinked files from XML files
- sgmltoken — Text tokenization.
- sgmlseg — simple segmenter
- sgmlsb — Sentence boundary marker.
- pesis — Trivial version of James Clark's sgmls.
- xmlnorm — XML normalizer.
- textonly — strip out markup
- simpleq — example program.
- simple — example program.
- sgsort — sort XML elements
- nslshowddb — display document type information
- II. Type reference
- Char — type representing characters in the XML internal encoding
- boolean — convenience type
- NSL_BI_Type — type discriminator for NSL_Bits and NSL_Items
- NSL_Item — type representing an SGML element, with contents.
- NSL_Data — type representing SGML element content
- NSL_Bit — type representing smallest transaction unit of event-level interface
- NSL_Query — type which represents a path in hierarchical document structure
- NSL_File — type which represents a stream for SGML input or output.
- NSL_Doctype — a private type which the parser uses to access and record information about the syntax and document type of one or more SGML
- NSL_ElementSummary — type representing information about a class of elements
- NSL_AttributeSummary — type representing information about an attribute
- NSL_EntitySummary — type representing information about an entity.
- NSL_Attr — linked list of attribute specifications
- III. Initialising LT XML
- NSLInit — function to initialise LT XML and set level of error reporting.
- NSLGetoptions — process standard options
- NSLInitNames — function to control the behaviour of attribute names.
- NSLClose — function to deallocate resources allocated by NSLInit
- IV. Opening and closing input and output streams
- OpenURL — function to open a stream to an XML document described by a URL.
- OpenStream — function to create an NSL_File from an existing standard I/O FILE *.
- OpenString — function to open a stream to or from an LT XML string.
- ReadProlog — read document prolog under user control
- SFFopen — function to open a stream to an XML document connected to a C stdio file handle.
- SFopen — function to open a stream to an XML document specified by a file name file handle.
- SFclose — function to close a file opened with SFFopen or similar.
- SFrelease — function to close file, releasing memory and (optionally) NSL_Doctype
- V. Document type information
- LoadDoctype — load document type from file.
- DoctypeFromDdb — function to read a description of an XML DTD which is contained in the .ddb file given by the file name filename.
- DoctypeFromFile — function to read a description of an XML DTD which is contained in the XML file given by the file name filename.
- VI. File positioning
- VII. URL Utilities
- GetFileURL — function that returns the URL associated with file.
- SetFileURL — function that sets the base URL associated with a file
- url_merge — function to fill in default information in a target URL by merging it with a base URL. The target information takes precedence.
- VIII. Reading SGML
- GetNextBit — function that returns the next NSL_Bit on a stream
- GetNextItem — function that returns the next NSL_Item on a stream
- ItemParse — function that fills in an NSL_Item of type NSL_inchoate
- IX. Queries
- ParseQuery — function to convert a query to internal form
- ParseQueryR — convert a query to internal form, allowing regular expressions as value of attributes
- ParseQuery8 — convert an 8-bit query to internal form
- ParseQueryR8 — convert an 8-bit query to internal form, allowing regular expressions as value of attributes
- GetNextQueryItem — function that fetches the next item matching a query, optionally printing non-matching content as it is read
- RetrieveQueryItem — function that searches an in-memory item for matches to a query
- RetrieveQueryData — retrieve NSL_Datas which match a query
- X. Printing
- PrintBit — Print a single bit.
- PrintStartTag — print the start-tag of a new item
- PrintItemStartTag — print the start tag of an existing item
- PrintEndTag — print the end-tag on an item
- PrintItem — Print an item.
- PrintText — Print text
- PrintTextLiteral — Print text literally with no expansion of markup.
- ForceNewline — ensure that a newline is put to the output file
- ForceOutput — flush output to an SGML stream
- XI. Attributes
- GetAttrStringVal — Get the value of an attribute
- GetAttrVal — get the value of an attribute.
- GetAttrSVal — get an explicitly present attribute value
- PutAttrVal — set an attribute value
- GetIDVal — get the value of the ID attribute on an item
- GetItemFromString — read an item from a string
- XII. Creating LT XML data structures
- NewNullNSLData — Create a new empty NSL_Data structure.
- NewNullNSLItem — create a new item
- NewTextNSLData — create a new NSL_Data containing some text
- NewItemNSLData — Creates a new empty Item
- XIII. Copying LT XML structures
- XIV. Structure navigation and Modification
- AddItemToEnd — Add an item after the existing daughters
- MoveDataTail — Move the data after a given location to a new location.
- InstallDataTail — Move an NSL_Data and its successors to a new location.
- InstallData — function to move the successors of an NSL_Data to a new location.
- LinkItem — create a data to hold an item, and link latter into place as child of an element
- LinkText — like LinkItem but for text data
- AddPCData — Add text below an item
- NextDFSNoChildren — Return the first piece of "real content" after a data.
- ObtainItem — find an NSL_Item within an NSL_Data
- ParentItem — Find the parent item of an item
- GetPCDataBelow — return first piece of text data below an item
- XV. Freeing LT XML data structures
- FreeBit — release memory associated with the item that a bit contains.
- FreeData — Free the data.
- FreeDoctype — Free the space occupied by a NSL_Doctype
- FreeItem — free an item and its contents
- FreeQuery — free a query
- XVI. Accessing the DTD
- DocumentIsNSGML — determine mode of document
- ElementContent — Return a (string) representation of the content model for an element.
- FindElementByName — element summary from name
- FindElementAndName — element summary from non-unique name
- ElementAttributes — return the attribute descriptions of an element summary
- FindAttrSpec — obtain summary of an attribute
- FindAttrSumAndName — obtain information about attribute of an element
- ElementExists — find out whether it does
- AttrExists — find out whether it does
- GetAttrDefVal — Get the default value for an attribute.
- GetAttrDeclaredValue — Get the declared value from an attribute summary.
- NewAttrVal — add attribute and value to item
- GetAttrDefaultValueType — Get default value type of an attribute
- AttributeName — return the attribute name
- GetAttrAllowedValues — find the allowed values for an attribute
- GetEntity — summary information about an entity.
- GetEntityValue — Get the value of an entity (as string)
- GetEntityDataType — Obtain a value to indicate the nature of an entity.
- XVII. Other functions
- ElementUniqueName — get the unique name of an element.
- ElementUniqueName8 — get the unique name of an element.
- AttrUniqueName — unique name for attribute
- AttrUniqueName8 — unique name for attribute
- ParseRCData —
- CurrentBitOffset — offset of current bit (for indexing)
- CurrentItemOffset — offset of current item (for indexing)
- XVIII. Manipulating Attributes
- SetAttrValue — set value within attribute
- GetAttrValue — Get the string value of an NSL_attr.
- CopyAttr — fresh copy of an attribute
- FindAttr — search for an attribute by name in an attribute list
- FreeAttr — free the memory associated with a list of attribute-value pairs
- XIX. Miscellaneous
- ParseInit — no longer documented
- List of Figures
- 4-1. The hierarchical structure of an example document.
- 4-2. CORPUS/DOC/TITLE/s
- 4-3. CORPUS/DOC/.*/s
- 4-4. ./.[1]/.[2]/.[0]
- 4-5. .*/BODY/s[0]
- 1. Items and Data
I. User guide
Chapter 1. Introduction
LT XML
LT XML is an integrated set of XML tools and a developer's tool-kit, including a C-based API It contains everything required to process a very wide range of conformant XML documents. The tools are intended to process all documents which are well formed according to REC-xml-19980210 (this is the latest available definition of XML). Future releases will track the XML standard if and when it changes. We can make no guarantees, but would particularly welcome feedback in cases where the behaviour of our library is found to deviate from that prescribed by REC-xml-19980210 . Such reports will be taken account of in bug-fixes and future releases.
How to read this document
This document assumes that the reader is familiar with SGML and the C programming language. Readers who wish to fully understand the way in which LT XML conforms to the XML 1.0 standard will need to obtain the defining document (REC-xml-19980210 ).The structure of this document is as follows.
The chapter headed The LT XML Architecture reviews the data architecture and the system architecture of LT XML
The first section deals with details of our approach to corpus encoding as applied to XML. This may be of more direct interest to computational linguists and speech technologists than to those concerned with generic applications of XML, but the idea of standoff annotation, which is emphasised in this chapter, is potentially of very wide applicability.
The section on system architecture gives a broad brush description of the way in which LT XML is constructed.
XML utility programs built using the LT XML API documents the user-callable utility programs provided in the LT XML system. We then give an overview of the data structures used to represent SGML structure in the API,
The chapter headed Query language gives a description of the LT XML query language which provides a convenient way of referring to elements of an SGML document, followed by an annotated program showing the use of the query language.
The next four chapters give a detailed description of the data structures and functions defined in the LT XML API.
Why we use XML
We use XML in the context of collecting, standardising, distributing and using very large text collections (10s and in some case 100s of millions of words in size) for computational linguistics research and development. The LT XML API and associated tools were developed to meet the needs that arise in such work, in the first instance for the creation, elaboration and transformation of markup for such collections (usually called corpora). Not only are the corpora we work with large, they have a very high density of markup (often each word has associated markup). We needed to support pipelined transformation programs running in batch mode (to allow modular, distributed software development) and specialised interactive editors to allow hand correction of automatically added markup.
Given the increasingly common use of XML and SGML as markup languages for text corpora, the question arises as to what is the best way of processing these corpora. For example, the task (common in linguistic applications) of tokenising a raw corpus, segmenting out the words therein and then looking the results up in a lexicon, becomes much more complex for SGML marked-up corpora (as indeed for any marked up corpus). Two main proposals have been suggested. Firstly, an approach which extracts the text data from a marked-up corpus in a form which then can be processed by pipelines of existing line-oriented programs using idiosyncratic markup for communication of structured results between tools. The second approach is that SGML markup should not only be retained and used as the input and output format for tool pipelines, but should also be used for inter-tool communication.
It is this second approach which we have taken in the LT XML library. It has the advantage that SGML is a well defined language which can be used for any markup purpose (as is XML, which is a simplified subset of SGML). Its value is precisely that it closes off the option of a proliferation of ad-hoc markup notations. A second advantage is that it provides a notation which allows an application to access the document at the right level of abstraction, attending to text and markup which are relevant to its needs, and ignoring that which is not. LT XML defines a query language and retrieval functions which make the selection of relevant content a straight forward task.
However, using SGML as the medium for inter-program communication has the disadvantage that it requires the rewriting of existing software, for example, UNIX tools which use a record/field format will no longer work. It is for this reason that we have developed an API library to ease the writing of new programs.
Furthermore, parsing SGML is very hard and slow if you handle the full range of constructions, validate as you go, and provide reasonable error messages and/or error recovery. Fortunately, parsing SGML is easy and fast if you handle only a subset of the full notation, eschewing validation. and parsing of XML is easy in all cases.
Accordingly, the basic architecture underlying our approach is one in which we use a simplified form of SGML, i.e. the Extensible Markup Language (XML) defined by PR-xml-970128. LT XML is closely related to another of our software packages, the Normalised SGML Library (LT NSL) LT-NSL, and shares the same API. LT NSL was developed before XML and has a slightly different definition of what normalised (or simplified) SGML is, and provides a tool for converting arbitrary SGML into a normalised form. LT XML provides support for processing XML documents as well. The LT XML library only supports processing XML documents and does not contain a program to convert SGML to XML (The job can be done using James Clark's SGML normalizer SX (See http://www.jclark.com/xml/)), and such a program would not be difficult to write by adapting mknsg, which is part of the LT-NSL add-on package.
Acknowledgements
This document has been created using SGML and DSSSL. This would not have been possible without the excellent DSSSL support provided by James Clark's Jade DSSSL engine (available at http://www.jclark.com/jade)
We are also very grateful to the Davenport group for providing and maintaining the DocBook DTD (see http://www.ora.com/davenport/) and to Norman Walsh for the the corresponding Modular DocBook Stylesheets (see http://nwalsh.com/docbook/dsssl/index.html ).
Thanks are due to the brave people (both within the Human Communication Research Centre and outside, who dared to use our research software for real tasks. Their feedback and tolerance is of course indispensable for the task of shaking out large and small bugs and infelicities in the implementation and design of the tools. What we distribute remains research software, with all that that implies, but it is largely thanks to our beta-testers and early users that any of it works at all.
Chapter 2. The LT XML Architecture
The Data Architecture
When we specify the data architecture of a corpus we are implicitly answering the question "How is all the information included in an XML coded corpus organised and stored?" It is helpful to spell out our assumptions about data architecture in corpus processing because the design of LT XML API is strongly influenced by these assumptions.
We are committed to using valid XML for all our corpora, but that still leaves a wide range of options as to just how the corpus components are organised as documents, and how those documents are stored as files.
We tend to steer a middle course between a monolithic comprehensive view of corpus data, in which all possible views, annotations, structurings etc. of a corpus component are combined in a single heavily structured document, and a massively decentralised view in which a corpus component is organised as a hyper-document, with all its information stored in separate documents, utilising inter-document pointers.
It is necessary to distinguish between files, which are storage units, XML documents, which may be composed of a number of files by means of external entity references, and hyper-documents, which are linked ensembles of documents.
Compound Annotation and Links
The implication of this is that corpus components can be hyper-documents, with low-density (i.e. above the token level) annotation being expressed indirectly in terms of links. In the first instance, this will be constrained to situations where element content at one level of one document is entirely composed of elements from another document. Suppose, for example, we had already tokenised a corpus file resulting in a single document:
Example 2-1. A tokenised corpus file
... <p id=p4> <w id=p4.w1>Time</w> <w id=p4.w2>flies</w> <w id=p4.w3>.</w> </p> ...
Example 2-2. A segmented corpus file
... <p id=p4> <phr id=p4.ph1 linkend=[d:p4.w1] type=n> <phr id=p4.ph2 linkend=[d:p4.w2] type=v> </p> ...
| Caution |
The notation used for links here is adopted for expository purposes only, should not be taken to imply anything about the behaviour of our tools. See the relevant section of the specification of the knit program, given in knit |
| Caution |
This capability is available in many proposals for linking mechanisms, including WD-xml-link-970731, but given the draft status of that document we do not at this stage wish to commit to the details of any linking mechanism. We will not gratuitously deviate from decisions made by the XML-LINK working group, and we certainly intend to implement a coherent and useful subset of the linking protocol which eventually emerges, but our primary goal is to support applications in computational linguistics and in corpus processing, so we will not necessarily track every detail. |
Example 2-3. Using links to reference multiple documents
... <word> <source linkend=[d:p4.w1]> <lex linkend=[x:en.lex.40332]> </word> ...
It follows from this that the lowest level of processing, tokenisation, will establish the base level of elements on the basis of which all further annotation will be based in the data architecture. In other words, up through tokenisation, processing will result in complete self-contained documents, with added information literally incorporated in the file stream. Note however that the proposed architecture is recursive, in that e.g. sentence-level segmentation could be expressed in terms of links into the phrase-level segmentation as presented above.
Versions
The data architecture needs to address not only multiple levels of annotation but also alternative versions at a given level. Since any linking mechanism will exploit XML's entity facilities to locate target documents, we can rely on these facilities in designing our versioning mechanism.
| Caution |
REC-xml-19980210 section 4.2.2 specifies the existence of PUBLIC and SYSTEM identifiers, and requires that system identifiers are URIs, but allows systems to ignore public identifiers. That is what LT XML does. We rely on system identifiers and relative URIs to achieve the goal. Arguably the same effect could be achieved more elegantly using an external mechanism for resolution of public identifiers, such as an SGML catalog. |
The System Architecture
When we use the term system architecture we are referring to the organisation of the software components which implement the LT NSL API. Our goal is to keep the API as stable as possible, but major developments in the SGML and XML world, not least REC-xml-19980210 mean that we have needed to make major changes under the hood. There have also been some additions and changes in LT XML API, some of which may impact upon user programs. But we have tried to keep this changes as minor and as transparent as possible, making the new functionality available without unnecessary disruption.
The system has three layers:
XML applications. These are tools which use the LT XML API. We provide a variety of example applications with the distribution. These applications are designed to cover some commonly occurring needs, but we anticipate that most users will sooner or later wish to build special purpose tools of their own. We recommend that you use one of the sample applications as a model for your own efforts.
The LT XML API layer. This is a collection of C functions and types which form a framework for generic SGML and XML processing tasks. As mentioned above, this has been relatively stable since 1.1. This interface was designed before XML existed, and has been honed and tested in successive releases of the LT NSL framework. Along with facilities similar to those proposed for SAX and DOM, the interface provides both a query language (see Query language). and high-level abstractions for input and output of SGML streams (see Document type information for XML documentsSince XML documents need not have explicit DTD information, the library has the ability create appropriate stand-in data structures as needed. These are used to record information about the elements and attributes which are encountered in the course of processing the document. In contrast to conventional DTDs, these data structures contain information which will be updated as new elements arrive.Because of this incremental update, coupled with the possibility that multiple documents may use the same NSL_Doctype structure, it is as well to pay careful attention to the possibility that information collected early in the processing of a stream may have changed at later points in its processing.).
Our intention is that programs which use the public interface defined for 1.1 should continue to work as before. Many of the XML applications in the distribution rely only on the public interface, but some (unfortunately) make direct use of functions internal to the LT XML library.
Note: Do as we say, not as we do. If you find yourself wanting to use functions which are not in the public API, please resist the temptation. If that doesn't work, get in touch, and we will consider extending the API in the next release. Or you can just go ahead and use the function, running the risk that we will remove or modify the function in some future release, breaking your program. In particular, this caveat implies that you should be discriminating about which of the provided applications you use as your model.
The LT XML API involves not only an event level abstraction similar to SAX and an element level abstraction similar to DOM, but also functions and types (notably ItemParse) which allow the programmer to shift between the two abstractions. As any amphibian will tell you, the ability to shift between two distinct modes of life gives access both to great opportunities and to great dangers.
In SGML processing the main opportunity is the gain in speed which is attainable by using the (highly efficient) event level interface to scan huge corpora for linguistically or technologically interesting sub-parts, then using the more convenient element level interface when the time comes to analyse the sub-parts which are returned. This frees us from the need to speculatively read large portions of document into memory.
The downside of the amphibian experience is the added complexity occasioned by the need for a dual capability, and the risk that one is less well adapted to either environment than are the full-time denizens of either land or sea. The second difficulty is not really relevant to our software, which achieves good performance at both the event level and the element level, but the need to switch levels has certainly led to an increment in complexity over a pure (SAX-like) event level interface or a pure (DOM-like) element level interface. When reading the code (which you are free to do if you choose to) it is a considerable aid to understanding if you recall that efficient level switching was part of the design specification of the library.
The final layer is an XML parser, called RXP, which is also available as a standalone component. This is an efficient, configurable XML parser (which aims to conform to REC-xml-19980210 ) and forms the bottom layer of our library. The parser itself is highly configurable, but does not provide a query language or the high-level input-output abstractions of LT XML API. The system can be configured either as an XML processor, whose main design goal is strict observance of the stipulations of PR-xml-970128 or as a more relaxed (and in our view much more useful) processor, which can, inter alia, pass up to the LT XML API the information which is needed by that layer.
Character encodings
LT XML 1.2 is Unicode capable. It can be compiled in 8- or 16-bit character mode. In 8-bit mode, the internal encoding is a superset of ASCII, in which all characters above 0xa0 are treated as name characters. Characters are not translated on input or ouput. This means that well-formed documents in ASCII and ISO-8859-N should work. In 16-bit mode, the internal encoding is UTF-16 and the supported input encodings are ISO-8859-N (1 <= N <= 9), UTF-16 and UTF-8.
Document type information for XML documents
Since XML documents need not have explicit DTD information, the library has the ability create appropriate stand-in data structures as needed. These are used to record information about the elements and attributes which are encountered in the course of processing the document. In contrast to conventional DTDs, these data structures contain information which will be updated as new elements arrive.
Because of this incremental update, coupled with the possibility that multiple documents may use the same NSL_Doctype structure, it is as well to pay careful attention to the possibility that information collected early in the processing of a stream may have changed at later points in its processing.
Chapter 3. simple.c -- A model LT XML application
This model application program (simple) has been written to demonstrate the use of the LT XML API. The program reads an XML file containing paragraph and word markup. It assumes that each word element has an attribute which contains part of speech (POS) information. The program then outputs a modified version of the input file where the text of each word element has been replaced by some text which shows the word and the POS tag associated to the word. For example, if the input file looks like:
<?xml version='1.0' encoding="ISO-8859-1" standalone="yes"?> <!DOCTYPE FILE [ <!ELEMENT FILE (HEADER,TEXT)> <!ELEMENT HEADER (#PCDATA)> <!ELEMENT TEXT (P*)> <!ELEMENT P (W*)> <!ELEMENT W (#PCDATA)> <!ATTLIST W TYPE CDATA #REQUIRED> ] > <FILE> <HEADER>blah blah</HEADER> <TEXT> <P> <W TYPE='det'>The</W> <W TYPE='nn'>cat</W> </P> </TEXT> </FILE>then the output file will look like:
<?xml version='1.0' encoding='ISO-8859-1' standalone='yes'?> <!DOCTYPE FILE [ <!ELEMENT FILE (HEADER,TEXT)> <!ELEMENT HEADER (#PCDATA)> <!ELEMENT TEXT (P*)> <!ELEMENT P (W*)> <!ELEMENT W (#PCDATA)> <!ATTLIST W TYPE CDATA #REQUIRED> ]> <FILE> <HEADER>blah blah</HEADER> <TEXT> <P> <W TYPE='det'>The/det</W> <W TYPE='nn'>cat/nn</W> </P> </TEXT> </FILE>Simple is not intended to be a particularly useful program, rather to be an example of the use of the LT XML API. The program can be called as follows:
simple [options] nsgmlfileAllowed options (all of which are optional) are:
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -t
name of attribute containing the POS information (default TYPE)
- -w
name of word element (default W)
- -f
print format for output words and their POS tags (default "%s/%s")
#include "nsl.h"
Include header file for LT XML public interface.
#include "ctype16.h"
Include header file for 16-bit character functions. These will be identical to the usual 8-bit functions if LT XML is compiled in 8-bit mode.
#include "string16.h"
Include header file for 16-bit string functions.These will be identical to the usual 8-bit functions if LT XML is compiled in 8-bit mode.
#include "lt-memory.h"
Non-public header file included to get sfree. Probably bad style, since sfree is almost indistinguishable from free.
#include "stdio16.h"
Analogues of the usual stdio.h functions but respecting the 8-bit, 16-bit character dichotomy.
static void usage(int exitval)
{
fprintf(stderr, "usage: simple [-he]
[-d ddb-file]
[-u base-url]
[-t type-attr]
[-w word-element]
[-f format]
[input-file]\n");
exit(exitval);
}The usage message
int main(int argc, char **argv) {
NSL_Bit *bit;
NSL_File inf=NULL, outf;
NSL_Doctype dct=NULL;
const Char *paraLabel,*wordLabel,*textLabel,*label,*tagAttr,*tagVal=NULL;
char *ptr;
Char buf[100];
int in_para=0,in_text=0,arg=1,in_word=0,len;
char *s;
NSL_Common_Options *options;Various variables. Earlier releases did not make the distinction between 8- and 16-bit characters. The Char type is either 16-bit or 8-bit, depending on the compilation switches used to build LT XML. char8 is always 8-bit, char16 is always 16-bit, and char is the ordinary character type of the C compiler you are using. In practice you will use Char for most program internal character strings, and char8 for most parameters passed in from a command line.
char* targ= (char *)"TYPE";
Default name of attribute carrying tag -- set with -t
char* warg= (char *)"W";
Default name of word element -- set with -w
const char* textFormat="%S/%S";
Format string for word, tag -- set with -f
NSLInit(0);
Initialise the LT XML SGML API. Programs should always do this before calling any other API function. This includes NSLGetoptions. In our experience mistakes involving this function are the most common source of hard-to-trace bugs in LT XML programs.
options = NSLGetoptions(&argc, argv, "hedu", usage); dct = options->doctype;
Process the standard command line arguments -h, for usage information,-e for user-specified output encoding, -d for a user-specified XML doctype (which can be provided in several forms, because of the possibility that we are dealing either with XML or nSGML), and -u for a user specified base URL (which will be used to resolve relative URLs in the processed document or documents). Store the information which has been recovered in the options structure.
for(arg = 1; arg < argc; arg++)
{
if(argv[arg][0] != '-')
break;
for(s = &argv[arg][1]; *s; s++)
switch(*s)
{
case 't':
if(arg+1 == argc)
usage(2);
targ=argv[++arg];
break;
case 'w':
if(arg+1 == argc)
usage(2);
warg=argv[++arg];
break;
case 'f':
if(arg+1 == argc)
usage(2);
textFormat=argv[++arg];
break;
default:
usage(2);
}
}Process tool-specific arguments for format string,name of element and attribute to use in construction of output.
switch(argc - arg)
{
case 0:
inf = SFFopen(stdin, dct, options->read_type, options->base_url);
break;
case 1:
inf = SFopen(argv[arg], dct, options->read_type);
break;
default:
usage(2);
break;
}If there is a remaining command line argument, interpret it as an input file name, otherwise open standard input as an XML stream. In either case we use the (possibly NULL) NSL_Doctype obtained from option processing. Passing a NULL doctype tells the system to (directly or indirectly) obtain the document type information by reading data from the stream which has just been opened. By default LT XML handles administrative details such as document type information, while user programs need concern themselves only with the content of documents.
You may wonder exactly when the document type information is read. In previous releases this happened when at file opening time, which is sometimes very inconvenient. In the current version a wider range of behaviours is available, controlled by flags passed to SFFopen or SFopen. See the function documentation for details of exactly what happens. The good news is that you should not need to change programs written to the earlier API, the even better news that, if you want, you can now get access to representations of document type data, unexpanded XML entities, processing instructions, and so on. See the function documentation to learn how to do this.
dct=DoctypeFromFile(inf);
We need the document type information from the input file in order to open the output file with the same DTD
if (DocumentIsNSGML(dct)) {
/* need upper case for attribute lookup */
ptr=targ;
while (*ptr) {
*ptr=Toupper(*ptr);
ptr++;
};
};
/* need upper case for tag lookup */
ptr=warg;
while (*ptr) {
*ptr=Toupper(*ptr);
ptr++;
};
};If we're reading nSGML, then case-folding upwards may have happened, so we need to case-fold our search strings. Toupper is a version of the standard toupper which respects the 16-bit or 8-bit nature of the internal Char data type.
outf=SFFopen(stdout, dct, options->write_type, "stdout");
Use the NSL_Doctype of the input file to establish the document type information of the output file.
textLabel=ElementUniqueName8(dct,"TEXT",4); paraLabel=ElementUniqueName8(dct,"P",1); wordLabel=ElementUniqueName8(dct,warg,0); tagAttr=AttrUniqueName8(dct,targ,0);
Get the unique name of the elements and the tag we care about. In the first two cases we provide the length of the strings used. In the last two cases we specify 0 as the length, with the effect that the true length will be measured by the called function.
Note that we are using the versions of these functions which consume 8-bit characters.
while ((bit=GetNextBit(inf))) {Loop round reading bits of the XML input text. A bit is either a single piece of text lacking SGML markup, or a single piece of SGML markup. (Usually, as here, markup types are start tag, end tag or processing instruction, but you can obtain a richer range of bits including comments and unexpanded entities if you choose to specify this in the flags passed to SFFopen or one of its relatives).
The body of the ensuing loop is a type-driven dispatch on the returned bit.
switch (bit->type) {
case NSL_start_bit:Case 1: We have found the start tag for an SGML element. Note that the item value of this bit is of type NSL_inchoate, meaning that unless you call ItemParse on it, it has just the start tag information, and no contents. If the potential contents are very large (for example, if the start tag is <BNC> and the document is indeed a substantial subset of the British National Corpus)this is an advantage, since you don't need to pull the whole thing into memory.
But when you do want the contents in memory, you should either call ItemParse before relying on the availability of the contents, or use GetNextItem in preference to GetNextBit. This reads complete subtrees into memory, assuming that size will not be a problem.
A third alternative, which in many ways offers the best of both worlds, is to use the still higher level query interface via GetNextQueryItem. The query processor is smart enough to search large corpora without necessarily reading large enclosing elements into program memory.
if ((label=bit->label)==textLabel) {Note that we're inside a <TEXT> element
in_text=1;
} else if (in_text &&
label==paraLabel) {note that we're inside a paragraph (<P>) inside <TEXT>/para>
in_para=1;
} else if (in_para &&
label==wordLabel) {We have found a word inside a text paragraph. Note this fact and save the POS tag stored on the item associated with the current bit. by looking up the tag attribute.
in_word=1;
tagVal=Strdup(GetAttrStringVal(bit->value.item,
tagAttr));
}Fall through to the next case (empty bits) because the printing code works for both cases. The associated empty item can't have text content, so it isn't worth inspecting it either for relevant attributes or to check their element name.PrintItem is smart and will print only a start tag for inchoate items, and will do the right thing for empty elements. That is, it prints a start tag (<foo>) if we are working with an item from a nSGML document, an empty tag (<foo/>) in the case of an XML document. In LT XML 1.2 items contain references to the document type of their originating document, mainly because of PrintItem's need to know how they should be printed.
case NSL_empty_bit:
PrintItem(outf, bit->value.item);
break;
case NSL_text_bit:
if (in_word) {
We strip trailing whitespace. Not the use of
Strlen and
is_xml_whitespace, which is
needed because we may be dealing with 16-bit characters
len=Strlen(bit->value.body);
while (is_xml_whitespace(bit->value.body[len-1])) {
bit->value.body[--len]='\000';
}
Now out the word and the POS tag(s).
We use
PrintText to keep the file output state up-to-date.
Sprintf(buf, InternalCharacterEncoding, textFormat,
bit->value.body,tagVal);
sfree((Char *)tagVal);
PrintText(outf,buf);
} else {
We have text in some other context -- print it unchanged.
PrintText(outf, bit->value.body);
}
break;
Final case. We have found an end tag, so we need to update the
variables which keep track of whether we are in a paragraph or in
a word. We make the (probably correct) assumption that words do not
nest, and the (very possibly incorrect) assumption that paragraphs
don't either. These assumptions make it OK to use boolean variables
to track context. At the cost of some extra complexity we could have
relaxed these assumptions, using a stack to keep track of context.
case NSL_end_bit:
if (in_para) {
if (bit->label==paraLabel) {
in_para=0;
} else if (bit->label==wordLabel) {
in_word=0;
}
}
We always print end tags when we see them. We don't handle processing
instructions in this code, although we could have added an extra case.
The defensive use of the macro SHOULDNT, which
prints a message and causes the program to exit, is OK in this
one-shot
tool,
but would be inappropriate in a program intended as a server.
PrintEndTag(outf,bit->label);
break;
default:
SHOULDNT;
}
FreeBit(bit);Bits are not themselves dynamically allocated by GetNextBit, but they may contain references to dynamically allocated data, in particular an enclosing NSL_Item. We call FreeBit to ensure that deallocation of this data proceeds in an orderly fashion.
} /* at the very end we need . . . */ SFclose(outf); return 0; }
Chapter 4. Query language
Queries
NSL queries are a way of specifying particular nodes in the SGML document structure. Queries are coded as strings which give a (partial) description of a path from the root of the SGML document (top-level element) to the desired SGML element(s). For example, the query
".*/TEXT/.*/P"describes any <P> element which occurs anywhere (at any level of nesting) inside a <TEXT> element which, in turn, can occur anywhere inside the top-level document element.
A query is a sequence of terms separated by /, where each term describes an SGML element. It is no accident that they resemble Posix pathnames. The syntax of queries is as follows:
<query> := <term> ( '/' <term> )* <term> := <bTerm> '*'? <bTerm> := <aTerm> ( '|' <aTerm> )* <aTerm> := <GI> <cond>? <GI> := <elementName> | '.' <cond> := '[' ( <index> | <atests> | <index> <atests> ) ']' <index> := <number> <atests> := <atest> ( ' ' <atest> )* <atest> := <aname> ( <operator> <aval> )? <operator> := [ '=' | '!=' | '~' | '!~' | '<' | '!<' | '>' | '!>' | '?' | '!?' ]That is, a query is a sequence of terms, separated by ``/''. Each term describes either an SGML element or a nested sequence of SGML elements. An item is given by an SGML element name, optionally followed by a list of attribute specs (in square brackets), and optionally followed by a ``*''. An item which ends in a ``*'' matches a nested sequence of any number of SGML elements, including zero, each of which match the item without the ``*''. For example ``P*'' will match a <P> element, arbitrarily deeply nested inside other <P> elements. The special GI ``.'' will match any SGML element name. Thus, a common way of finding a <P> element anywhere inside a document is to use the query ``.*/P''. Aname (attribute name) and aval (attribute value) are as per SGML . A term which consists of a number of aTerms separated by '|' will match anything that any one of the aTerms match
| Caution |
On Windows 95 systems one should note that this is the vertical bar character '|' (decimal 124) and not the split vertical bar character '�'(decimal 166). |
A condition with an index matches only the index'th sub-element of the enclosing element. Index counting starts from 0, so the first sub-element is numbered 0. Conditions with indices and atests only match if the index'th sub-element also satisfies the atests. Attribute tests are not exhaustive, i.e. P[rend='it'] will match <P n='45' rend='it'> as well as <P rend='it'>. They will match against both explicitly present and defaulted attribute values, using string equality. Bare anames are satisfied by any value, explicit or defaulted. Matching of queries is bottom-up, deterministic and shortest-first.
A number of operators are defined to compare the values of attributes against constant strings in the query, these are:
- =
string equality
- !=
string inequality NB if -r is specified as option to sggrep, then = and != mean ~ and !~ respectively
- ~
regular expression matching
- !~
negated regular expression matching
- <
numeric less than ( non-numbers are treated as zero, as per atof)
- !<
numeric not less than ( means >= )
- >
numeric greater than
- !>
numeric not greater than ( means <= )
- ?
user defined comparison function
- !?
negated user defined comparison function
For user defined comparison function we use the function which is the value of the global variable
boolean (* LTNSL_User_defined_comparison)
(const char* ival, const char* qval) = NULL;The function call *LTNSL_User_defined_comparison(ATTR_VALUE, QUERY_VALUE) should return true if ATTR ? VALUE is true, else false. To use this user defined operator you need to write your own program which calls the API; the '?' operator is not meaningful to the sggrep program.
Note the difference between numeric and string equality e.g. the query ".*/A[ x = 0 ]" does not find <a x=foo/> , because we do string equality, but ".*/A[ x !> 0 x !< 0 ]" would find it, since the numeric value of foo is zero when converted by atof, and hence is neither less than nor greater than zero.
Examples of LT XML queries
In this section we show some examples of queries, assuming the following DTD.
<!ELEMENT CORPUS (DOC+)> <!ELEMENT DOC (DOCNO,TITLE,BODY,IT,NI) > <!ELEMENT DOCNO (#PCDATA) > <!ELEMENT TITLE (s+) > <!ELEMENT BODY (s+) > <!ELEMENT IT (#PCDATA) > <!ELEMENT NI (#PCDATA) > <!ELEMENT s (#PCDATA|w)* > <!ELEMENT w (#PCDATA) > <!ATTLIST BODY id ID #IMPLIED > <!ATTLIST IT id ID #IMPLIED> <!ATTLIST w rend CDATA #IMPLIED>
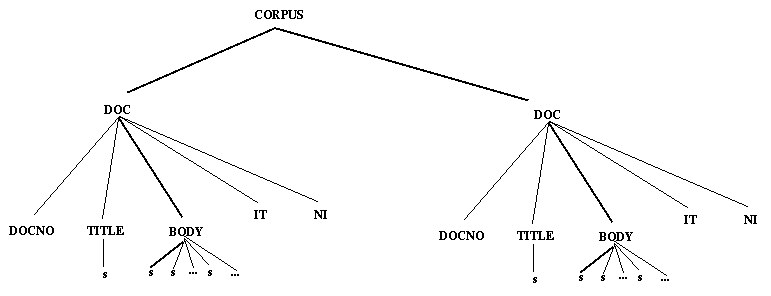
The SGML structure of a sample document which uses this DTD is shown in Figure 4-1
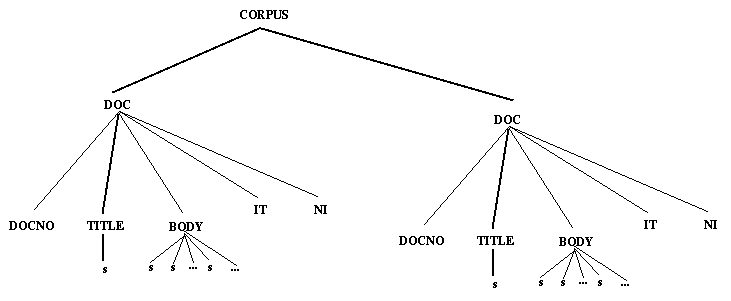
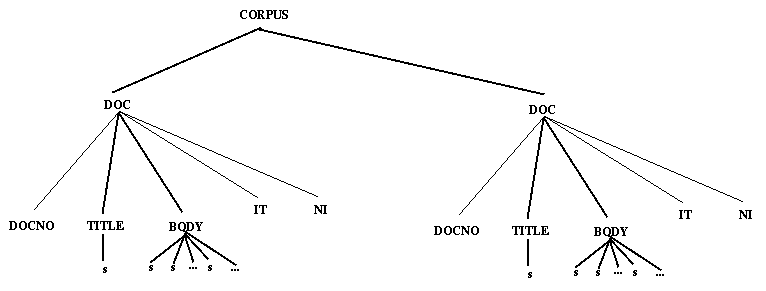
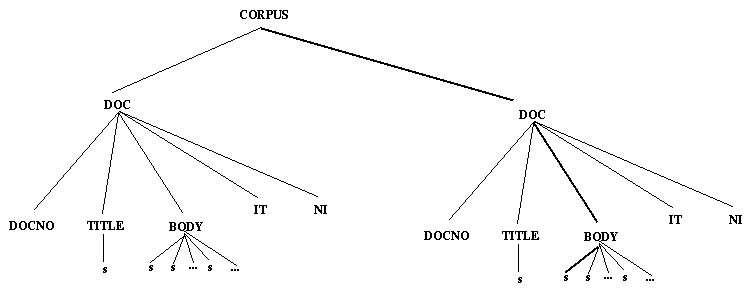
The query CORPUS/DOC/TITLE/s means all s elements directly under TITLE's directly under DOC. This is shown graphically in Figure 4-2. The LT XML query functions return the indicated items one by one until the set denoted by the query is exhausted. The query CORPUS/DOC/./s means all s's directly under anything directly under DOC, as shown in Figure 4-3. The query CORPUS/DOC/.*/s means all s's anywhere underneath DOC. .* matches all finite sequences of . For the example document structure this means the same as CORPUS/DOC/./s, but in more nested structures this would not be the case. An alternative way of addressing the same sentences would be to specify .*/s as query. We also provide a means of specifying the Nth node in a particular local tree. So the query ./.[1]/.[2]/.[0] means the 1st element below the 3rd element below the 2nd element in a stream of elements, as shown in Figure 4-4. This is also the denotation of the query CORPUS/DOC[1]/BODY[2]/s[0] assuming that all our elements are s's under BODY under DOC, which illustrates the combination of positions and types. The query .*/BODY/s[0] refers to the set of the first elements under any BODY which are also s's. The referent of this is shown in Figure 4-5. Additionally, we can also refer to attribute values in the square brackets: .*/s/w[0 rend=lc] gets the initial elements under any <s> element so long as they are words with rend=lc (perhaps lower case words starting a sentence).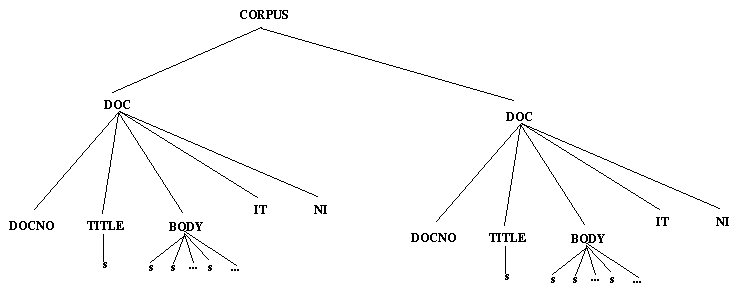
The query language is designed to provide a small set of orthogonal features. Queries which depend on knowledge of prior context, such as ``the third element after the first occurrence of a sentence having the attribute quotation'' are not supported. It is however possible for tools to use the lower-level API to find such items if desired. The reason for the limitation is that without it the search engine might be obliged to keep potentially unbounded amounts of context. If this proves frustrating, see sgrpg, which provides ways of constructing more complex queries. If this is not enough, you can always write your own programs using the LT XML API.
Chapter 5. simpleq.c - A model LT XML application using queries
The following program simpleq.c shows how the LT XML API query functions can be used. It does not exercise all the facilities, but does enough to be worth explaining.
#include "nsl.h"
Include header file for LT XML public interface.
#include "ctype16.h"
Include header file for 16-bit character functions. These will be identical to the usual 8-bit functions if LT XML is compiled in 8-bit mode.
#include "string16.h"
Include header file for 16-bit string functions.These will be identical to the usual 8-bit functions if LT XML is compiled in 8-bit mode.
#include "lt-memory.h"
Non-public header file included to get sfree. Probably bad style, since sfree is almost indistinguishable from free.
static void usage(int exitval)
{
fprintf(stderr, "usage: simpleq [-he] "
"[-d ddb-file] "
"[-u base-url] "
"[-t type-attr] "
"[-w word-element] "
"[-f format] "
"[input-file]\n");
exit(exitval);
}The usage message
int main(int argc, char **argv) {
NSL_File inf=NULL, outf;Input and output files. Crucial to initialize inf to NULL, since this will be relied on when file is opened.
NSL_Doctype dct=NULL;
It used to matter that dct was NULL, but this variable is now set as part of the standard option processing.
NSL_Query qu; NSL_Item *item; const Char *tagAttr, *tagVal=NULL; char8 qustr[100], *ptr; Char buf[100]; int arg,len; char *s; NSL_Common_Options *options;
Various variables. Note that query strings have element type char8, but that buffers have element type Char, which is 16-bit or 8-bit depending on the compilation switches when LT XML was built. This distinction is new in LT XML 1.2.
char* targ= (char *)"TYPE";
Default name of attribute carrying tag -- set with -t
char* warg= (char *)"W";
Default name of word element -- set with -w
const char* textFormat="%S/%S";
Format string for word, tag -- set with -f
NSLInit(0);
Initialise the LT XML SGML API. Programs should always do this before calling any other API function. This includes NSLGetoptions. In our experience mistakes involving this function are the most common source of hard-to-trace bugs in LT XML programs.
options = NSLGetoptions(&argc, argv, "hedu", usage); dct = options->doctype;
Process the standard command line arguments -h, for usage information,-e for user-specified output encoding, -d for a user-specified XML doctype (which can be provided in several forms, because of the possibility that we are dealing either with XML or nSGML), and -u for a user specified base URL (which will be used to resolve relative URLs in the processed document or documents). Store the information which has been recovered in the options structure.
for(arg = 1; arg < argc; arg++)
{
if(argv[arg][0] != '-')
break;
for(s = &argv[arg][1]; *s; s++)
switch(*s)
{
case 't':
if(arg+1 == argc)
usage(2);
targ=argv[++arg];
break;
case 'w':
if(arg+1 == argc)
usage(2);
warg=argv[++arg];
break;
case 'f':
if(arg+1 == argc)
usage(2);
textFormat=argv[++arg];
break;
default:
usage(2);
}
}Process tool-specific arguments for format string,name of element and attribute to use in construction of output.
switch(argc - arg)
{
case 0:
inf = SFFopen(stdin, dct, options->read_type, options->base_url);
break;
case 1:
inf = SFopen(argv[arg], dct, options->read_type);
break;
default:
usage(2);
break;
}If there is a remaining command line argument, interpret it as an input file name, otherwise open standard input as an XML stream. In either case we use the (possibly NULL) NSL_Doctype obtained from option processing. Passing a NULL doctype tells the system to (directly or indirectly) obtain the document type information by reading data from the stream which has just been opened. By default LT XML handles administrative details such as document type information, while user programs need concern themselves only with the content of documents.
You may wonder exactly when the document type information is read. In previous releases this happened when at file opening time, which is sometimes very inconvenient. In the current version a wider range of behaviours is available, controlled by flags passed to SFFopen or SFopen. See the function documentation for details of exactly what happens. The good news is that you should not need to change programs written to the earlier API, the even better news that, if you want, you can now get access to representations of document type data, unexpanded XML entities, processing instructions, and so on. See the function documentation to learn how to do this.
dct=DoctypeFromFile(inf);
We need the document type information from the input file in order to open the output file with the same DTD
if (DocumentIsNSGML(dct)) {
/* need upper case for attribute lookup */
ptr=targ;
while (*ptr) {
*ptr=Toupper(*ptr);
ptr++;
};
};If we're reading nSGML, then case-folding upwards may have happened, so we need to case-fold our test string. Toupper is a version of the standard toupper which respects the 16-bit or 8-bit nature of the internal Char data type.
outf=SFFopen(stdout, dct, options->write_type, "stdout");
Use the NSL_Doctype of the input file to establish the document type information of the output file.
strcpy8(qustr,".*/TEXT/.*/P/.*/"); strcat8(qustr, warg); qu=ParseQuery8(dct,qustr); tagAttr=AttrUniqueName8(dct,targ,0);
Construct a query, which looks for words anywhere inside paragraphs anywhere inside a text, and look up the unique name for the tag attribute for subsequent use.ParseQuery handles case-folding if necessary. It uses the passed-in document type to determine whether we have nSGML input.
In the next section we read items of the SGML input text. When we find an item which matches the query we execute the body of the while loop. Items which do not match are automagically written to the output stream by GetNextQueryItem, Each call of GetNextQueryItem creates a new item, which it is the responsibility of the programmer to free once it has been used.
while( ( item=GetNextQueryItem(inf, qu, outf ) ) ) {
read the item
Char *word=(Char*)item->data->first;
len=Strlen(word);
while (is_xml_whitespace(word[len-1])) {
word[--len]='\000';
}When we are inside the text of a word element,strip off trailing whitespace.
tagVal=GetAttrStringVal(item,tagAttr);
Look up the value of the attribute that carries tag information for this item.
Sprintf(buf,InternalCharacterEncoding,textFormat,word,tagVal);
construct a string representing the word and its tag.
item->data->first = buf;
Install the new string as the item's content.
PrintItem(outf, item);
Now print the item. Note that we use PrintItem to write the modified item to the output file. This is in order to keep the XML output state up-to-date. Note that the code here assumes that each word element contains only text and no embedded SGML markup. More complex code could cope with this more complex possibility.
item->data->first = 0;
If we were to leave our statically allocated buffer as a child of the item, FreeItem would try to recursively free it. The consequences of this are undefined, but probably disastrous on at least some of the platforms that we support. So we break the link.
sfree(word);
Conversely, the storage for word was allocated by GetNextQueryItem, so we need to free it in the appropriate way by calling sfree.
| Caution |
As previously mentioned, sfree is not part of the LT XML API. An alternative solution, which is the one that we would probably adopt in practice, is to graft back word as child of item before calling FreeItem |
FreeItem(item); } /* end while */
Each item is freed.
SFclose(outf); return 0; }
At the very end we need to close the output XML stream. We don't bother to explicitly free the NSL_Query or to close the input XML stream, since cleanup will be handled adequately when the program exits. A long-running server program aiming to provide the same service would, as usual, need to be more precise in its handling of the boundary conditions. Examples of how to do this are provided in the function documentation.
II. LT XML reference
This section of the manual is a reference document for the tools (XML utility programs built using the LT XML API), types (Type reference) and functions (subsequent sections, starting with Initialising LT XML).
The function reference sections include descriptions of all the functions exposed in the LT XML API. If not otherwise specified, those functions below which return a pointer, will return a NULL pointer in case of error, but see below.
- Table of Contents
- I. XML utility programs built using the LT XML API
- II. Type reference
- III. Initialising LT XML
- IV. Opening and closing input and output streams
- V. Document type information
- VI. File positioning
- VII. URL Utilities
- VIII. Reading SGML
- IX. Queries
- X. Printing
- XI. Attributes
- XII. Creating LT XML data structures
- XIII. Copying LT XML structures
- XIV. Structure navigation and Modification
- XV. Freeing LT XML data structures
- XVI. Accessing the DTD
- XVII. Other functions
- XVIII. Manipulating Attributes
- XIX. Miscellaneous
I. XML utility programs built using the LT XML API
The tools in the bin directory are:
a program for querying XML files, sggrep.
a tool for linking elements of hypertext documents. knit This is based on WD-xml-link-970731 and not on the very recent newer versions of XML LINK.
a suite of tools for linguistic annotation, including a tokeniser (sgmltoken), a toy segmenter (sgmlseg actually a perl program) and a sentence boundary finder (sgmlsb);
a simple version (element structure, text and limited attribute information only) of nsgmls called pesis
a program to output all the text (and none of the markup) from an XML file,textonly;
two illustrative applications, simple and simpleq , whose source code (in src/appl/simple.c and src/appl/simpleq.c) which intended as a starting point for application developers.
Note: The C source files in the data directory, used for testing, also demonstrate some simple uses of the LT XML API;
a utility program nslshowddb for printing .ddb files.
Note: LT XML does not provide a means for generating .ddb files. This is part of the functionality of our toolkit, which also allows normalization of arbitrary SGML files. The component is available as an add-on package. We make this division primarily in order to improve the portability of the XML component of the toolkit.
two programs sgmltrans and sgrpg, which provide alternative methods of subsetting and transforming XML files into alternative formats;
a program sgcount for counting the amount of markup in a file;
a program sgsort for sorting sub-trees of SGML documents;
a program xmlnorm for trivial normalisation of XML files, useful for checking well-formedness.
Finally, there are other SGML-aware programs which have been developed by the Language Technology Group, which make use of the LT XML library, for example a partial parser, a part-of-speech tagger and text indexing software. Our SGML and tokenisation technology was also heavily used in our high-scoring entry to the named-entity recognition subtask of the MUC-7 Message Understanding Conference.
Contact the manager of the Language Technology Group directly for further details.
- Table of Contents
- sggrep — works like the grep program in searching a file for regular string expressions. However, unlike grep , it is aware of the tree structure of XML files.
- sgmltrans — translate XML files into another format.
- sgrpg — systematically transform input document to changed output document
- sgcount — count elements in an XML file.
- knit — process compound documents using hyperlinks
- unknit — create hyperlinked files from XML files
- sgmltoken — Text tokenization.
- sgmlseg — simple segmenter
- sgmlsb — Sentence boundary marker.
- pesis — Trivial version of James Clark's sgmls.
- xmlnorm — XML normalizer.
- textonly — strip out markup
- simpleq — example program.
- simple — example program.
- sgsort — sort XML elements
- nslshowddb — display document type information
sggrep
Name
sggrep -- works like the grep program in searching a file for regular string expressions. However, unlike grep , it is aware of the tree structure of XML files.Synopsis
sggrep [-h] [-u base-url] [-d doctype] [-v] [-n] [-r] [-m mark-query] [-a element-name] [-q query] [-s sub-query] [-t regexp] [--] [inputs...]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -n
Don't force a newline between output matches. The default is to print a newline between each match.
- -v
Invert sense of sub-query+regexp, see below for details.
- -q query
Pattern on items to select, basically path of terms separated by /, each term representing a sequence of SGML elements. See section Query language for the details of what a query looks like.
- -r
Attribute values in queries are regular expressions.
- -s sub-query
If present, selects sub-elements of query-selected item for regexp to match.
- -t regexp
Regular expression to match against text directly contained in query-selected item (if no sub-query) or in any sub-query selected sub-element of query-selected item. If empty (i.e. '' on Unix or "" in a Windows console command processor) matches anything, including empty elements, indeed this is the only way to get empty elements if required.
Note: sggrep supports two different command syntaxes. The one given above (new in LT XML 1.2) trades brevity for explicitness. The alternative allows very concise expression of common needs, especially when used in pipelines.
sggrep [-h] [-u base-url] [-d doctype] [-v] [-n] [-r] [-m mark-query] [-a element-name] query [ sub-query] [ regexp] [--] [inputs...] [< input] [> output]
The concise version dispenses with the key letters for the three query arguments (previously addressed by -q,-s and -t). This is very convenient in pipelines, like:
or (under a Windows console command processor, where the quote character is ")Example 1. A concise sggrep command line (Unix)
zcat nt.xml.gz |sggrep '.*/CHAPTER/V' '.*/PARA' Comforter | sgcountExample 2. A concise sggrep command line (Windows)
zcat nt.xml.gz |sggrep ".*/CHAPTER/V" ".*/PARA" Comforter | sgcountWhen using the second, terse, form, the -- is required unless both regexp and/or sub-query are explicitly provided. If not, the program might treat input file names as part of the query.
We continue to support the brief syntax for backward compatibility and and for the benefit of those who greatly value brevity. If you use the
Description
Since the output of sggrep is XML, it can be used as input to another call of sggrep, thus allowing more complex queries to be built up in stages.
Brief summary of query syntax
Terms separated by /
<term>:=<GI><cond>?'*'?
<GI>:=<elementName>|'.'
<cond>:='['<index>|<atests>|<index> <atests>']'
<index>:=<number>
<atests>:=<atest>(' '<atest>)*
<atest>:=<aname>( ['='|'!=']
<aval> )? Aname and aval are as per SGML, except that if the -r flag is given, aval are regular expressions. A GI of . matches any tag. A condition with an index matches only the index'th sub-element of the enclosing element. Attribute tests are not exhaustive, and will match against both explicitly present and defaulte attribute values, using string equaLity. Bare anames are satisfied by ANY value, explicit or defaulted. Terms ending with * match any number of links in the chain, including 0.
sgmltrans
Synopsis
sgmltrans [-h] [-u base-url] [-d doctype] [-r rulefile] [-p] [inputs...]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -r rulefile
specifies the name of as file which describes a set of rules for processing the XML input.
- -p
If specified, he program will merely print out the rules which are being used, and not process the input
Description
sgmltrans is a program for translating XML files into some other format (which could be HTML or LaTeX or ...). It is loosely based on COST and other SGML programs, in that one specifies actions to do at SGML start tags, end tags and text content. In sgmltrans, these actions are restricted to printing some text to the output stream.
The sgmltrans rule file consists of an ordered list of rules. A rule consists of an LT XML query (see section Query language) which describes the elements to which the rule will apply; and a pair of format strings, which specify the strings that will be printed when we encounter (a) a start tag for a matching element, and (b) when we encounter an end tag.
The format strings are printed as literal strings with the exception of the two special characters $ and \.
The character \ forms part of an escape sequence characters depending on the following character:
| \n is replaced by a newline. |
| \t is replaced by a tab. |
| \\ is replaced by a single \. |
| for any other X \X is left unchanged as \X. |
The format strings may contain special variables denoting the name of the SGML element and the values of attributes. These are $gi and $attributeName, where attributeName is the name of an attribute defined for the element (if the input file is $notsgml; the attribute name should be upper case, because the normalization process will upper-case the attribute names in the input). These variables will be replaced by either the element name or the value of the attribute for an SGML element which matches the rule. The lines containing format strings must start with a tab.
For example, given the rule:
.*/W
""
"/$TAG\n"
the input file:
<W TAG="A">The</W>
<W TAG="B">cat</W>
will be converted into
The/A
cat/B
For each element found in the input file, the rules are tried in their order in the rule file, until one is found whose query matches the element. Once a rule has matched, no more rules are applied to this element.
Every rule file should contain a default rule which matches all elements, which will be used for elements which do not match any earlier rule. The default rule
.*
""
""
prints nothing for elements which match it. Since all other rules
are tried before the default rule, this is often as requiredFinally, rules can also be specified to apply particular transformations to text bodies of elements. A rule query which ends in # matches text content. These rules are called data rules. Instead of a pair of start/end format strings, data rules contain a set of text transformations, currently just literal strings, but hopefully in future general regular expressions, of the form
"searchString" --> "replacementString"will also be supported.
Each transformation is applied globally to the text content before it is printed.
So for example:
.*/W/#
"<" --> "$<$"
could be useful if you were trying to produce LaTeX source from an
XML file. sgmltrans is still an experimental program.
Thus it is not
particularly efficient and its functionality is limited in a number
of ways. We intend to improve it on the basis of experience. For
more complex manipulation of SGML files see sgrpg.sgrpg
Synopsis
sgrpg [-h] [-u base-url] [-d doctype] [-D cmdfile-dtd] [-v] [-r] [-f cmdfile [query | sub-query | regexp | out-fmt | oarg]] [> input] [< output]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -D cmdfile-dtd
(if specified) the location of the DTD for the pattern action file specified with -f. If the -D ddbfile is specified, use this, otherwise use the doctype given by the input file.
Note: The previous version used an environment variable for the default DDBFILE, because we have no way to stop it being used when the rule file is XML. Now you have to either have an NSL declaration or pass the -D flag.
In LT XML 1.2 the rule file can be XML or nSGML, as can the input file. We hope this is an esoteric point, but our tests reveal that all combinations of XML and nSGML can work as you would expect. One crucial proviso is that sggrep will fail disastrously unless the attributes defined for the elements of the control file are either explicitly present or provided with default values in the DTD. This is a leftover from nSGML, which did not allow dynamic addition of DTDs to the doctype of a file. A future release will provide a version of sggrep which handles this situation better. [1].
- -v
Complement operation. If this option is specified then only elements which do not match the regexp are output. Default is normal matching.
- -r
Interpret values of attributes in queries as regular expressions. Default is to treat attribute values as plain strings.
- -f cmdfile
The command file which contains the pattern-action statements that make up the sgrpg program. This option is an alternative to the use of explicit command line arguments to indicate the transformation intended.
There are two different methods of calling sgrpg; in the first one one specifies the query and the output format on the command line; in the second (using the -f option) more complex sequences of queries and formats can be specified in a control file. Details of both methods are given below below.
If using -f then the -D option should appear before -f.
- query
an NSL query which selects the set of matching elements from the input stream.
- sub-query
an NSL query which selects sub-elements of query-selected item for regexp to match.
Note: The documentation of 1.1 erroneously claims that sgrpg provides default values for its arguments in the same way as sggrep. It doesn't: you have to supply everything.
- regexp
A regular expression to match against text directly contained in in the sub-query selected sub-element of query-selected item.
Note: Once again, this is not optional, contrary to the claims of the documentation in 1.1.
- out-fmt
A format string, similar to that for printf, but supporting %s with the usual modifiers for manipulation of field length, justification and so on, %~ to stand for newline (literal newlines would be removed by attribute value normalization), and %% as an escape mechanism for when you really need a % in the string.
- oargs
A sequence of arguments to match out-fmt, allowing specification of various parts of the matching material (see examples below). Either <GI>, <DATA>, or attribute name.
Description
sgrpg is an SGML selection and transformation tool, it is still experimental and we intend to extend it on the basis of experience.
sgrpg is an XML-aware query and transformation program. It allows one to select a set of SGML elements from a document and optionally to transform them into a new format. Sgrpg allows nested queries and lists of alternative queries, and hence allows more complex queries than sggrep (sggrep). In addition, it allows one to specify what to output when one finds one of the SGML elements which match one of the queries. This means that sgrpg is the tool of choice when converting SGML into different file formats (e.g. LaTeX or another text formatting language). It is a filter, i.e. it reads from stdin and writes to stdout.
| Warning |
This version of sgrpg has an incompatible change: line breaks in format attributes will no longer work, and the format specifier %~ should be used instead. The reason for this change is:
|
Examples
These examples document the old and less complex command-line syntax.
sgrpg ".*/W" ".*" ".*" "%s/%s" "<DATA>" TYPE < temp.sgm
prints out a list of all the <W> elements anywhere in the input document, in the form of word/type one per line.
sgrpg ".*/P/S/W" ".*" "theatre" "%s" "<DATA>" < temp.sgm
prints out a list of all the <W> elements (inside <P> and <S> which contain the string "theatre".
Queries are as for sggrep, but in addition allow a <term> of the form '#'. A query which ends in an term '#' matches textual content.
Format of sgrpg control files:
A sgrpg control file is an XML or nSGML file based on the sgrpg.dtd DTD (in the lib/ltxml10 subdirectory which is installed,either by default in /usr/local, or at a user specified location selected by an argument provided to configure, when you install LT XML ). The file consists of a sequence of <Q> elements, which is interpreted as a set of queries/transformations that sgrpg is to apply to the input.
A <Q> element consists of subqueries or output format elements.
Subqueries consist of <S>, <G> or <OR> elements.
An <S> element represents a sub-query. The LINK attribute of an <S> can be one of DEPSER, DEPSEQ, DEPPAR, or INDEPENDENT(default). By specifiying different values for this attribute it is possible to control the way in which a set of sub-queries are interpreted.
- INDEPENDENT
means start searching at same point in containing element, regardless of success or failure of other subqueries.
- DEPSER
means start where previous subquery finished, provided it succeeded.
- DEPSEQ
means must match next sub-elt immediately after the previous match.
- DEPPAR
means start at same point in containing element, provided others so far have succeeded, i.e. AND.
A <G> element groups together a group of queries and/or format statements which are to be repeated. EXP, ID and REF attributes can be specified for <OR>, <S> or <G>. EXP is one of ONE, OPT, PLUS, STAR which allows one to state a Kleene operator on the desired matches. REF is a #CONREF attribute which refers to another element for doing repetition and self-inclusion.
<OR> elements describe a short-circuit disjunction of sub-queries, in which sub-queries are attempted in order until one succeeds, or until the list of queries is exhausted.
Format elements consist of <F> statements, which describe output strings which are printed when we find an element which matches the query. <F> elements can contain <A> elements, which describe where to find the data required by the format string. So
<F S="{%s/%s}"><A TYPE=DATA/><A A=TYPE/></F>
defines a format string, the %s fields of which are filled from the
data content of the matching element and the value of the TYPE
attribute respectively.<F> elements can alternatively be of the form <F TYPE=ELT [DN=number]>, which mean print the matching element (or the numberth daughter, if number is specified) as normalised SGML. <F TYPE=STAG [DN=number]> means print the entire start tag, GI and all explicitly given attribute/value pairs. <F TYPE=ETAG [DN=number]> means print the end tag.
<A> elements come in the following forms
- <A TYPE=GI/>
the name of the SGML element.
- <A TYPE=DATA [DN=number]>
The numberth bit of text content of the element (default value of number is 0, i.e. the first).
- <A A=Attribute_name/>
The value of the attribute called attribute_name.
- <A TYPE=PATN [RN=number]/>
the numberth match from a previous regular expression match.
Any of the above can have a VTYPE attribute, with a value of one of STRING, INTEGER, or FLOAT. If specified then the value of the <A/>is converted to that type if possible.
Example: Printing titles
<?XML VERSION="1.0"?> <!doctype sgrpg SYSTEM "file:sgrpg.dtd,xml"> <Q Q=".*/DIV1"> <S Q=".*/TITLE"><F S="DIV1: %s "><A TYPE=DATA/></F></S> <S Q=".*/DIV2"> <S Q=".*/TITLE"><F S="DIV2: %s "><A TYPE=DATA/></F></S> <S Q=".*/DIV3"> <S Q=".*/TITLE"><F S="DIV3: %s "><A TYPE=DATA/></F></S> <S Q=".*/DIV4"> <S Q=".*/TITLE"><F S="DIV4: %s "><A TYPE=DATA/></F></S> </S></S></S></Q>prints out the titles of <DIV1> ... <DIV4> elements.
Example: Everything except comments
The following rule file gives the query to print out the entire contents of an XML file, except for <comment> elements.
<?XML version="1.0"?> <!doctype sgrpg SYSTEM "file:sgrpg.dtd"> <Q> (1) <OR ID='TOP'> <S Q='COMMENT'></S> (2) <G><S POLARITY='N' Q='.*/COMMENT'></S> (3) <F TYPE='ELT' DN='-1'></F></G> <G> (4) <F TYPE='STAG' DN='-1'></F> (5) <OR EXP='STAR'> (6) <S Q='./.' LINK='DEPSEQ'> (7) <OR REF='TOP'> (8) </S> <S Q='./#' LINK='DEPSEQ'> (9) <F><A TYPE='DATA'/></F> </S> </OR> <F TYPE='ETAG' DN='-1'></F> (10) </G> </OR> </Q>
- (1)
- The top level <q> (which has a default query of '.') will match (because of the <or>), any of the enclosed disjuncts.
- (2)(3)
- Either a comment element, in which case we are done, something which does not contain any comments, which we print, or something deserving more detailed attention.
- (4)
- This branch of the disjunction is for elements containing a mixture of comments and other stuff.
- (5)
- When we encounter the start tag we print it.
- (6)
- The EXP='STAR' modifier indicates that the processing within the scope of the OR is to be applied to successive child elements in turn.
- (7)(9)
- The first of these queries matches SGML elements proper, and the second PCDATA pseudo elements. The LINK='DEPSEQ' attributes make sure that elements are processed sequentially, and that every element and every piece of PCDATA is processed.
- (8)
- The top-level transformation is applied recursively to any SGML elements which are encountered. This is specified by providing REF='TOP' as an attribute for the OR element. The effect of this is to include the OR element which has ID='TOP'. and to re-apply the transformation in the context of the child whic is currently being processed.
- (9)
- When PCDATA (specified by the trailing # on the query) is encountered, it is simply printed out.
- (10)
- Finally we print the end-tag to balance the start tag which was printed when we began to process an element containing contents. The unwinding of the recursion on element contents ensures that all the start tags printed on the way to the leaves of the document are balanced by their corresponding end tags.
Given the file
<?XML version="1.0"?> <!DOCTYPE min [ <!ELEMENT min (div+)> <!ELEMENT div ((comment|p)*)> <!ATTLIST div foo CDATA #IMPLIED> <!ELEMENT p (#PCDATA|comment|div)*> <!ELEMENT comment EMPTY> ]> <min> <div> <p>baz<comment/></p> <p> some text </p> </div> <div foo=' '><comment/></div> </min>the commands
sgrpg -f test.rule < test.sgm > test.nsgwill result in
<?xml version="1.0"?> <min> <div> <p>baz</p> <p>some text</p> </div> <div foo=' '> </div> </min>I.e. we have printed everything except <comment> elements.
sgcount
Synopsis
sgcount [-o 012] [-t] [inputs...]
- -t
Means count top level element only.
- -o 012
0 means default printout format, 1 means tag names and counts only, 2 means global total number of tags only.
Description
It is often useful to count the number of occurances of SGML markup in a file, for example when constructing <tagusage> entries for the TEI DTD. Sgcount is intended to provide this information.
If the -t option is specified then, sgcount only counts the elements at the top level of the document. This form is useful for running after sggrep, to see how many matching elements have been found.
The default output consists of lines of the form SGML element name TAB frequency TAB identified frequency where frequency is the number of times that SGML element name occurs in the input file and identified frequency is the number of times that it occurs with an explicit attribute of type ID.
A line of totals is printed after the statistics for individual tags.
The -o option allows user control of the information printed. 0 means default printout format, 1 means tag names and counts only, 2 means the total number of tags only.
knit
Synopsis
knit [-h] [-u base-url] [-d doctype] [-r attr-spec...] [-i attr-spec...] [input.xml]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -r
means that the original element is to be replaced (entirely) by the material yielded by following the HREF attribute. Nothing of the original element survives.
- -i
means that the material yielded by following the HREF attribute is to replace the content of the original element. The start and end tags, with attributes, of the original element survive.
Description
Insert linked-to material specified by a subset of the XML-LINK standard. knit takes a single input file making use of zero or more target files to generate output which is an edited copy of the input file. The output draws its content from the input, except that elements which have an xml:link="simple" attribute are inspected, and if they have attributes matching an attr-spec they are replaced by the resource specified by the hred attribute, which must be of the form url#id(name)[..id(name)]. It is possible to specify two forms of resource:
url#id(name): which denotes an element in the target file which has a particular ID. This element is incorporated into the output file.
url#id(from)..id(to): which denotes a range of element which appear in the target file. These elements are incorporated in the output file.
Note: The situation is unclear when, as is allowed by REC-xml-19980210 , the processor does not have the information necessary to unambiguously identify the relevant attribute. Users of knit are strongly advised to ensure that the target document does contain a sufficiently explicit DTD. If this requirement proves impossibly onerous, we would be interested to hear why, and to address the matter in some future release of the system.
Note: attr-specs are of the form name=value,name=value,... Quoting should be allowed in them but isn't.
If no -r or -i options are given, the default is
-r show=replace,actuate=auto -i show=embed,actuate=auto
Example
This example is a cut-down version of a need which arose in LTG and CSTR's SOLE (Spoken Intelligent Labelling Explorer). We have a file of tokenised words, as shown below. We call this the target file. In general knit may use multiple target files to generate its output. It finds target files by following links which are specified in the input file. In this case, which is typical, there is just one target file.
<?xml version='1.0'?> <!DOCTYPE solexml SYSTEM "solexml.dtd" []> <solexml> <language name="english"/> <wordlist> <w id="w394w398" punc="," whitespace=" " prepunctuation="">Indeed</w> <w id="w402" punc="0" whitespace=" " prepunctuation="">the</w> <w id="w406" punc="0" whitespace=" " prepunctuation="">term</w> <w id="w410w414w418" punc="'" whitespace=" " prepunctuation="`">jewelry</w> <w id="w422" punc="0" whitespace=" " prepunctuation="">encompasses</w> <w id="w426" punc="0" whitespace=" " prepunctuation="">an</w> <w id="w430" punc="0" whitespace=" " prepunctuation="">extraordinary</w> <w id="w434" punc="0" whitespace=" " prepunctuation="">range</w> <w id="w438" punc="0" whitespace=" " prepunctuation="">of</w> <w id="w442" punc="0" whitespace=" " prepunctuation="">accessories</w> <w id="w446" punc="0" whitespace=" " prepunctuation="">which</w> <w id="w450" punc="0" whitespace=" " prepunctuation="">people</w> <w id="w454" punc="0" whitespace=" " prepunctuation="">have</w> <w id="w458" punc="0" whitespace=" " prepunctuation="">used</w> <w id="w462" punc="0" whitespace=" " prepunctuation="">to</w> <w id="w466" punc="0" whitespace=" " prepunctuation="">decorate</w> <w id="w470w474" punc="." whitespace=" " prepunctuation="">themselves</w> </wordlist> </solexml>
and a corresponding file marked up with (minimal) information about the information status of the terms. We call this the input file. It contains two types of markup sem-elem and eraseable. Since the input file has less dense markup, it is easier on the eye than the target file.
<?xml version='1.0'?> <!DOCTYPE solexml SYSTEM "solexml.dtd" [<!ENTITY w "words.xml">]> <solexml> This is a type of brooch that was popular around the 1960s. It might not be instantly recognisable as "jewelry"; but it is important to remember that jewelry doesn't have to be expensive or elaborately crafted. Indeed, the term <sem-elem type="new-term" href="&w;#id(w410w414w418)">`jewelry' </sem-elem> <eraseable href="&w;#id(w422)..id(w470w474)"> encompasses an extraordinary range of accessories which people have used to decorate themselves. </eraseable> </solexml>
Note that the href attribute of the sem_elem in the input file is "&w;#id(w410w414w418)" which refers to w410w414w418 in the file words.xml (because words.xml is the expansion of the entity &w;) This ID is also present in the target file. When knit processes this specification it will obtain the corresponding element from the target file. In this example, for reasons which will be explained later, the element from the target replaces the original contents of the corresponding element from the input file.
The href attribute of the eraseable is "&w;#id(w422)..id(w470w474)", which refers to the range from w422 to w470w474 in the file words.xml. When knit processes this specification it obtains all the elements in this range. In this example, for reasons which will be explained later, these elements from the target completely replace the corresponding element from the input file. This behaviour differs from that seen earlier, in which the start and end tags of the original sem_elem are wrapped around the content obtained from the target file. In a moment we will see how this behaviour is obtained.
These link syntaxes are the only ones which we currently support. Other forms of link syntax may in due course be added.
In this example both files use the same DTD, which is shown below.
Note: Nothing prevents you from using different DTDs for the different files, but if you do this, it is as well to check the output of knit using a validating XML parser, since you will have created a document which is based on two separate and potentially incompatible DTDs.
<!ELEMENT solexml (#PCDATA|language|wordlist |sem-elem|w)*>
<!ELEMENT wordlist (w)*>
<!ELEMENT w (#PCDATA)>
<!ATTLIST w id ID #REQUIRED
punc CDATA #REQUIRED
whitespace CDATA #REQUIRED
prepunctuation CDATA #REQUIRED>
<!ELEMENT language EMPTY>
<!ATTLIST language name CDATA #REQUIRED>
<!ENTITY % replaceHyperlinkAttrs
'href CDATA #IMPLIED
xml:link CDATA #FIXED "simple"
show CDATA #FIXED "replace"
actuate CDATA #FIXED "auto" '>
<!ENTITY % embedHyperlinkAttrs
'href CDATA #IMPLIED
xml:link CDATA #FIXED "simple"
show CDATA #FIXED "embed"
actuate CDATA #FIXED "auto" '>
<!ELEMENT sem-elem (#PCDATA|w)*>
<!ATTLIST sem-elem type (new-term) #REQUIRED
%embedHyperlinkAttrs; >
<!ELEMENT eraseable (#PCDATA|w)*>
<!ATTLIST eraseable %replaceHyperlinkAttrs; >The DTD specifies the actions which knit will perform by defining attributes on the sem-elem and the eraseable element. Here we are asking it to replace the contents when it sees sem-elem, but to replace the element itself when it sees eraseable. It is convenient to use XML parameter entities to abbreviate the oddly-named attributes required by XML-LINK, especially since the relevant attribute names and the syntax of the values have changed frequently in the past.
We invoke knit with the simple command line:
knit sem-elem.xml
obtaining the output
<?xml version='1.0'?> <!DOCTYPE solexml SYSTEM "solexml.dtd" [<!ENTITY w "words.xml">]> <solexml> This is a type of brooch that was popular around the 1960s. It might not be instantly recognisable as "jewelry"; but it is important to remember that jewelry doesn't have to be expensive or elaborately crafted. Indeed, the term <sem-elem type='new-term' href='words.xml#id(w410w414w418)'> <w id='w410w414w418' punc="'" whitespace=' ' prepunctuation='`'>jewelry</w> </sem-elem> <w id='w422' punc='0' whitespace=' ' prepunctuation=''>encompasses</w> <w id='w426' punc='0' whitespace=' ' prepunctuation=''>an</w> <w id='w430' punc='0' whitespace=' ' prepunctuation=''>extraordinary</w> <w id='w434' punc='0' whitespace=' ' prepunctuation=''>range</w> <w id='w438' punc='0' whitespace=' ' prepunctuation=''>of</w> <w id='w442' punc='0' whitespace=' ' prepunctuation=''>accessories</w> <w id='w446' punc='0' whitespace=' ' prepunctuation=''>which</w> <w id='w450' punc='0' whitespace=' ' prepunctuation=''>people</w> <w id='w454' punc='0' whitespace=' ' prepunctuation=''>have</w> <w id='w458' punc='0' whitespace=' ' prepunctuation=''>used</w> <w id='w462' punc='0' whitespace=' ' prepunctuation=''>to</w> <w id='w466' punc='0' whitespace=' ' prepunctuation=''>decorate</w> <w id='w470w474' punc='.' whitespace=' ' prepunctuation=''>themselves</w> </solexml>
Note that elements from the target file have been incorporated in the output, and that the sem-elem is still present in the output file, while the eraseable is absent.
unknit
Synopsis
unknit [-h] [-u base-url] [-d doctype] [basefile] [targetGI] [sourceGI] [<input-file] [> output-file]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- basefile
the file which holds the elements to which hyperlinks in the output will refer.
- targetGI
Occurrences of this SGML element in input will be replaced by hyperlinks back to corresponding elements in the basefile.
- sourceGI
Specifying a sourceGI means that only targetGI occuring inside sourceGI will be hyperlinked. Occurrences of targetGI which are not inside sourceGI elements will be left untouched.
Usage
unknit is a program which creates hyperlinked XML files from XML or nSGML files. The present version is still somewhat experimental. It turns out that combining hyperlinked files to a single stream (the job of knit) is a daily occurrence in our work on multimedia corpora, but that the need for picking apart a stream into different levels does not arise nearly so much [2]. However, suppose test.w.xml is an XML file which contains <w> markup around words; test.s.xml is an XML file which contains <s> markup around sentences (consisting of a sequence of <w> elements. Running the command:
unknit test.w.xml w s < test.s.xml > testout.s.xmlwill create the XML file testout.s.xml which contains the <s> markup from test.s.xml, but with all <w> elements replaced with hyperlinks back to test.w.xml.
Note: This command is old, and we have never used it much. It should work, but be cautious.
sgmltoken
Synopsis
sgmltoken [-h] [-u base-url] [-d doctype] [input file]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- input-file
If provided, the name of the file to be tokenized. Otherwise standard input is tokenized.
Description
All text inside TEXT elements is tokenized, i.e. split into tokens and marked up with C elements.
Example
For example, if the relevant part of the input file is
<TEXT> <BODY> <W TYPE="red">Some</W> <W TYPE="blue&green &indint;">text</W> <W TYPE='foo&bar;nizz'>please</W> </BODY> </TEXT>then the corresponding output will be
<TEXT> <BODY> <W TYPE="red"> <C ID='C2.T1'>Some</C> </W><W TYPE="blue&green ∫"> <C ID='C4.T1'>text</C> </W><W TYPE="foobarvalnizz"> <C ID='C6.T1'>please</C> </BODY> </TEXT>Note that the C elements have been systematically given appropriate IDs.
We make no claim that sgmltoken is a general useful tokenizer, it can function as a placeholder for a high-quality tokenizer, such as those used by LT CHUNK and LT POS.
Note: sgmltoken is built only when the system is compiled in 8-bit mode. It is not built when the system is compiled in 16-bit mode.
Contact the manager of the Language Technology Group directly for further details.
sgmlseg
Description
A Perl program which identifies words in text that has already been marked up by sgmltok or similar. Main interest is to demonstrate the fact that XML (or nSGML) is a conveniently regular input format even for tools which do not use the LT XML library, and the fact that such tools can freely partcipate in pipelines of tools.
| Caution |
We provide this only for some platforms because of the dependency on Perl. You probably won't miss it anyway, since it is didactic rather thena useful. |
sgmlsb
Synopsis
sgmlsb [-h] [-u base-url] [-d doctype]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
Description
adds S elements to a file which has already been tokenized with sgmltoken and segmented with sgmlseg.
We make no claim that this is a useful sentence boundary marking application. But it fits into the same place in pipelines as would a substantial sentence boundary marker as reported by Mikheev or by David Palmer.
Contact the manager of the Language Technology Group directly for further details.
pesis
Synopsis
pesis [-h] [-u base-url] [-d doctype]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
xmlnorm
Synopsis
xmlnorm [-h] [-u base-url] [-d doctype]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -V
Validate the input
Description
Apparently trivial program which takes XML input and outputs the same By default entities will be expanded and such validation as LT XML usually performs will occur.
Note: Validation is much more extensive in the newest releases of LT XML There is a new 'V' flag to NSL_Getoptions which allows tools to transparently support validation. xmlnorm is the first to use this facility.
textonly
Synopsis
textonly [-h] [-u base-url] [-d doctype] [-t tag] [-s c] [-x]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -t
If present, output only text which is found inside this element.
- -s string
If present, output the specified string as separator between successive pieces of text.
Description
Outputs text, but not markup from the input XML file. Especially useful values for the -c parameter are ' ' (one space), '\n' (a newline) and '' (the null string). Care is sometimes needed to get newlines past your favourite shell and into this program, but once this is achieved, typical results (e.g. words one per line) are very satisfying. This is an effective route out of the XML world and back to the newline delimited one record per line world of tools like grep and awk.
simpleq
Synopsis
simpleq [-h] [-u base-url] [-d doctype] [-t tag-attribute] [-w word-element] [-f format-string ]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -t
Name for attribute under which POS tag is found.
- -w
Name for element on which POS attribute is found.
- -f
Output format string.
simple
Synopsis
simple [-h] [-u base-url] [-d doctype] [-t tag-attribute] [-w word-element] [-f format-string ]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- -t
Name for attribute under which POS tag is found.
- -w
Name for element on which POS attribute is found.
- -f
Output format string.
sgsort
Synopsis
sgsort [-h] [-u base-url] [-d doctype] [domain] [element] [key]
- -u base-url
Use this URL as the base URL when resolving relative URLs. The value specified for this argument is passed to SFFopen or a similar stream creation function.
- -d doctype
Use the doctype found in this file in preference to anything on the input stream. The file can be any of
an XML file an XML file with no body (i.e. just a doctype) an NSG file a .ddb file - -h
Print usage information for the program.
- -e
Do not expand entities.
- domain
The container for the elements to be sorted
- element
The type of the elements to be sorted
- key
The attribute to follow to obtain the sort key for the selected elements.
Description
Find the elements of type element which occur within domain and output them in alphabetical order of their key attributes.
nslshowddb
Description
Display the contents of an nSGML .ddb file. If you are a long-time nSGML user you will know that these files are binary repositories for document type information, and will appreciate the need to see this information when unexpected things happen to your documents.
It is of little interest to a first-time user of LT XML, since the toolkit provides no means for generating such files. The need for such files has diminished with the advent and wide dissemination of XML. An add-on toolkit will continue provide the additional functionality for nSGML users who still need to generate .ddb files.
II. Type reference
This section introduces all the types which are manipulated via the LT XML API. They are included in the C header file nsl.h. (and we provide further header files for those who need to use the internal structure of our 'private' types -- although we do not anticipate much real need for such use).
Note: The details of 'private' type declarations can be found in the internal header file sys/nsllib.h. If you need their internal structure and know what you are doing (i.e. you have read the source files), you should include this header file in your C program as well as the public nsl.h.
In LT XML 1.2 we have adjusted the structure of the include files so that 'private' include files are kept in the sys subdirectory of the main ltxml10 include directory. The latter will be automatically searched if you use the Makefile.usr supplied with the distribution. The requirement to explicitly write sys/... is imposed partly in order to help programmers notice that they are moving beyond the official API.
We'd like to know if you encounter real reasons for using the internal structure of our 'private' types. We hope you won't have to: if you do it probably indicates a deficiency in the API.
Figure 1 illustrates the most important relationships between the key types. The types in question are: NSL_Items,NSL_Datas and the tags which mark their types.
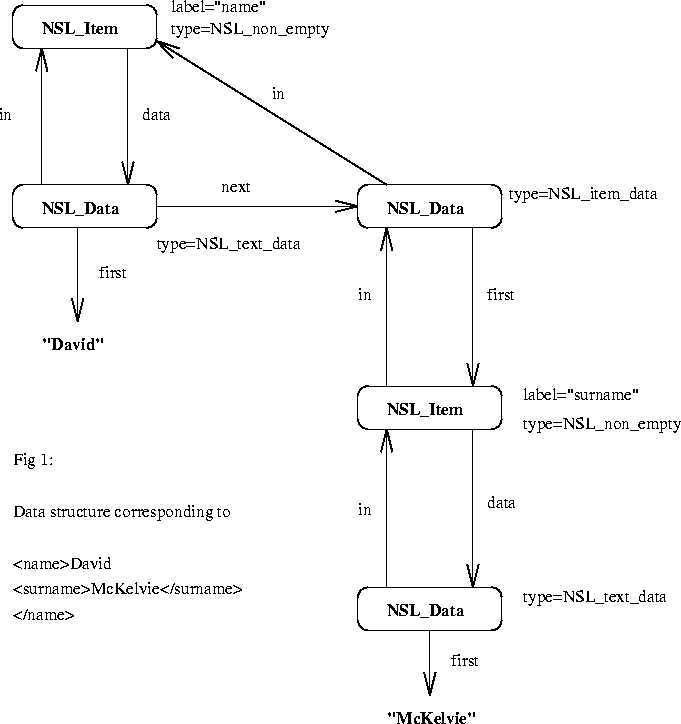
In order to view an SGML document as a hierarchical structure, the LT XML API constructs a C data structure made up of NSL_Item and NSL_Data data structures (see NSL_Item and NSL_Data) which mirrors the tree structure of the document.
The tree structure involves one more level of indirection than you might expect. In a standard tree structure nodes point directly to their sub-nodes, so we would expect to see pointers from items directly some representation of their sub-items. To simplify destructive operations on the sub-items, we choose to represent the sub-items as a linked list. The obvious way of doing this in C is to require that each NSL_Item include a field which points to its right sister (or NULL if there is none). Any item could then be used to access either the contents of the item itself or the linked list of sister items.
We decided that this potential ambiguity between the item and the list of which it is a member is confusing, and likely to promote error. Our design makes NSL_Items containers for linked lists of NSL_Datas. NSL_Datas wrap several different types of SGML content to provide a uniform interface, and they provide the links which connect successive sub-items of a particular item. Functions which want to manipulate lists of items take and return NSL_Datas as their arguments (see Structure navigation and Modification) while functions which work with items take and return NSL_Items.
The NSL_Data data structure represents a chunk of SGML element content, i.e. either an NSL_Item or some other piece of content. Crucially, everything except NSL_Items ( text, CDATA, comments, document type information,and processing instructions),can be adequately represented for our purposes by a simple text string. Thus the only NSL_Datas which contain recursive structure are those which point to a NSL_Item.
For flexibility NSL_Items and NSL_Datas include pointers to their parents. The parent of an NSL_Item (if present) is always an NSL_Data, and an NSL_Data always has an NSL_Item as its parent. (see NSL_Item and NSL_Data for full descriptions of these structures)
- Table of Contents
- Char — type representing characters in the XML internal encoding
- boolean — convenience type
- NSL_BI_Type — type discriminator for NSL_Bits and NSL_Items
- NSL_Item — type representing an SGML element, with contents.
- NSL_Data — type representing SGML element content
- NSL_Bit — type representing smallest transaction unit of event-level interface
- NSL_Query — type which represents a path in hierarchical document structure
- NSL_File — type which represents a stream for SGML input or output.
- NSL_Doctype — a private type which the parser uses to access and record information about the syntax and document type of one or more SGML
- NSL_ElementSummary — type representing information about a class of elements
- NSL_AttributeSummary — type representing information about an attribute
- NSL_EntitySummary — type representing information about an entity.
- NSL_Attr — linked list of attribute specifications
Char
Description
The type Char is introduced for characters which can appear in SGML text. It is controlled by a compile-time switch: if the LT XML system is compiled in 16-bit mode then Char is an unsigned 16-bit type. If it is compiled in 8-bit mode, Char is equivalent to char. Unsigned char would have been better than char, but causes too many compiler warnings in applications.
Externally provided argument names are of type char8* since there is currently no reliable cross platform solution for passing 16-bit command lines to an LT XML tool. Conversion functions strdup_char8_to_Char and strdup_Char_to_char8 are provided, as are variants of the common string.h functions which accept Char arguments (in string16.h). See the function documentation and the example programs for more information.
boolean
Description
The type boolean is defined as:
#define boolean int
It is used to mark the difference between functions which return a truth value and those which return a richer error code
NSL_BI_Type
Synopsis
typedef enum {NSL_bad,
/* The first are for bits */
NSL_start_bit, NSL_end_bit, NSL_empty_bit,
NSL_eof_bit, NSL_text_bit, NSL_pi_bit,
NSL_doctype_bit, NSL_comment_bit,
/* the rest of these are Item types */
NSL_inchoate, NSL_non_empty, NSL_empty, NSL_free} NSL_BI_Type;Description
The LT XML data structures NSL_Item and NSL_Bit (defined in subsequent sections) come in various types. These types have tags drawn from the enumerated type above. LT XML 1.2 includes new bit types for comments and document type information as part of support for applications which need to see everything in the document. See File flags for more detail.
NSL_Item
Synopsis
/* Tree node corresponding to an SGML element */
typedef struct NSL_Item {
const char *label; /* The SGML element name */
const NSL_Doctype doctype;
NSL_BI_Type type;
struct NSL_Data *data; /* The SGML element content */
NSL_ElementSummary defn; /* The NSL summary definition of
the element type */
struct NSL_Attr *attr; /* Linked list of actual (as opposed to defaulted)
attributes for the element */
struct NSL_Data *in; /* dominating NSL_Data if any */
} NSL_Item;
- item.label
Contains the name of the SGML element which this item is describing, e.g. ``P''. This field is constant across all occurrences of the same element type. (For efficiency, the comparison used to establish equality should be == in default mode, but the less efficient Strcmp is necessary in the backward compatibility mode invoked by specifying NSL_use_strings as argument to NSLInitNames).
- item.doctype
A pointer to the document type of the NSL_Item in question. This is a new field in LT XML 1.2. It will not necessarily be supported in future versions of the API.
- item.type
Describes what sort of item this is. NSL_Items of type NSL_inchoate describe an SGML start tag e.g. <P type=indented>, but not the contents of this element. NSL_Items are initialised with this type value. If LT XML decides, after checking the DTD, that this item corresponds to an empty SGML tag (i.e. one with an EMPTY content model), then the type field is set to NSL_empty. If non-empty, then once LT XML has read the entire contents of this SGML element (i.e. as far as the corresponding end tag), then the type is set to NSL_non_empty. Finally, NSL_Items that have been 'freed', by FreeItem will have type NSL_free. You will (we think) never encounter NSL_Items of this last type unless you have made a programming mistake.
- item.data
a pointer to the representation of the content of this SGML element, i.e. a linked list of NSL_Data structures.
- item.defn
an internal representation of the nature and details of the DTD definition of the SGML element (see Accessing the DTD)
- item.attr
A pointer to a linked list of NSL_Attr structures which describes the attributes explicitly attached to this element, i.e. not defaulted attributes (see Attributes)
- item..in
A pointer to the NSL_Data structure which contains this item, i.e. the content of the SGML element which contains this element.
Description
The NSL_Item type describes an SGML element and all its contents in a document, i.e. it represents a complete subtree of the document structure.
NSL_Data
Synopsis
typedef enum {NSL_undefined,NSL_text_data,NSL_item_data,
NSL_pi_data,NSL_comment_data,
NSL_cdata_data,NSL_free_data} NSL_Data_Type;
typedef struct NSL_Data {
int ref;
NSL_Data_Type type; /* type pointed to by first */
struct NSL_Data *next; /* next NSL_Data or NULL */
void *first; /* could be either text or an NSL_Item per type field */
NSL_Item *in; /* dominating item */
} NSL_Data;
Values
- data.ref
Used internally and should not be modified by user code. It is in fact the position number of the NSL_Data in its enclosing NSL_Item.
- data.type
Tells us whether this NSL_Data} refers to an SGML element NSL_item_data, to some character data (NSL_text_data),to the contents of a processing instruction(NSL_pi_data), to the contents of an SGML comment (NSL_comment_data), to the contents of a CDATA marked section (NSL_cdata_data) or to an erroneously freed piece of data (NSL_free_data, which obviously shouldn't happen unless something has gone wrong).
Note: The flags for comments and CDATA are new in this version. They exist as part of the new support for applications such as XML structure editors. This support allows the system to return a full representation of the SGML document being processed.
- data.next
The next document chunk which is at the same level of nesting in the SGML document structure. It is NULL if this is the last daughter of its parent.
- data.first
Points to a string (an array of Char) or to an NSL_Item which is the content of this data element.
- data.in
The NSL_Item which contains this data element.
Description
Represents a chunk of SGML element content, i.e. either an SGML element or a piece of text without element structure. They are organised into a linked list of mixed NSL_Items and text in mixed content, with the additional guarantee that there will be no bare text element-only content.
There may also be NSL_Datas of type NSL_pi_data, which represent SGML processing instructions. In this case the data.first pointer points to the string body of the processing instruction.
NSL_Bit
Synopsis
typedef struct NSL_Bit {
NSL_BI_Type type;
boolean isCData; /* only valid if type NSL_text_bit */
union {
NSL_Item *item; /* type NSL_start_bit */
Char *body; /* text, pi */
void * data; /* NSL_internal_bit */
} value;
const Char *label; /* valid only if type NSL_start_bit or NSL_end_bit */
/* or NSL_empty_bit */
} NSL_Bit;Description
NSL_Bits describe the basic chunks of an SGML document as follows:
- NSL_start_bit
An SGML start tag, e.g. <P type=indent>, for non-empty elements.
- NSL_end_bit
An SGML end tag, e.g. </P>
- NSL_empty_bit
An SGML milestone tag, e.g. <xref/>
- NSL_text_bit
A piece of text with no SGML element content.
- NSL_pi_bit
An SGML processing instruction e.g. <?tabset tab=8?>
- NSL_doctype_bit
The text of an SGML doctype bit.
- NSL_comment_bit
The text of an SGML comment e.g. <!-- do not throw bytes at this notice -->
- NSL_bad
Unless you do unusual things, you should never see this value, but see Error handling for more information on how to adjust the default error-reporting behaviour of LT XML.
- NSL_eof_bit
Only set when we have reached end of file.
An NSL_Bit points to either Char data (type NSL_text_bit NSL_doctype_bit,NSL_comment_bit or NSL_pi_bit) or to an NSL_Item (type NSL_start_bit or NSL_empty_bit).
The label field (when defined, i.e.for NSL_start_bit,NSL_empty_bit or NSL_end_bit) is the name of the corresponding SGML element.
If you work at the event level rather than the element level, you gain a degree of flexibility, but must take on more responsibility for ensuring that any XML documents which you generate are well-formed and/or valid.
NSL_Query
Description
An NSL_Query is a data structure which is the internal representation of a query. A query is a description of a path in the SGML document structure.
NSL_Query is defined as a pointer to a private data structure, i.e. all you can do with them is to pass them around between NSL functions.
NSL_File
Description
Defined as a pointer to a private data structure, i.e. all you can do with them is to pass them around between NSL functions.
In LT XML 1.2 there is a much enriched ontology of file types, intended to cover a variety of processing needs for both input and output. See File flags for detailed information.
NSL_Doctype
Name
NSL_Doctype -- a private type which the parser uses to access and record information about the syntax and document type of one or more SGMLDescription
An NSL_Doctype A container for the type of information usually found in an SGML Document Type Description (DTD).NSL_Doctype is defined as a pointer to a private data structure, i.e. all you can do with them is to pass them around between NSL functions. Since DTDs are optional in XML mode, the library also uses this type to record DTD-style information which it infers during processing of document content. Under some, but not all, circumstances this discovery of DTD information will be accompanied by a pattering of warning messages (see Error handling for more detail).
Note: We lied about the typedef. In reality the declaration of NSL_Doctype is not a typedef, but rather a preprocessor macro, which means it cannot be used to declare more than one variable at a time. Using a real typedef interacts badly with C's const modifier.
NSL_ElementSummary
Description
The NSL_ElementSummary data structure provides access to document information about an SGML element. In XML mode this information may be determined incrementally, but in nSGML mode the information is predetermined by the original DTD.
NSL_ElementSummary is defined as a pointer to a private data structure, i.e. all you can do with them is to pass them around between NSL functions (see Accessing the DTD)
Note: We lied about the typedef. In reality the declaration of NSL_ElementSummary is not a typedef, but rather a preprocessor macro, which means it cannot be used to declare more than one variable at a time. Using a real typedef interacts badly with C's const modifier.
NSL_AttributeSummary
Description
The NSL_AttributeSummary data structure describes the structure of an SGML attribute as defined in the DTD.
NSL_AttributeSummary is defined as a pointer to a private data structure, i.e. all you can do with them is to pass them around between NSL functions (see Accessing the DTD).
Note: This one really is a typedef. The problem with const doesn't arise.
NSL_EntitySummary
Description
Defined as a pointer to a private data structure, i.e. all you can do with them is to pass them around between NSL functions (see Accessing the DTD).
Note: This one really is a typedef. The problem with const doesn't arise.
NSL_Attr
III. Initialising LT XML
Contents
This section describes the functions which are used to allocate and deallocate the resources which LT XML needs in order to run. It also describes NSLInitNames, which makes available a backward compatibility mode in which a measure of efficiency is sacrificed for programmer convenience. Use of this mode is deprecated.
Error handling
Error handling in LT XML is systematic and principled: All interface functions now may return a detectable error value, usually either NULL, FALSE or EOF depending on their declared return value type (pointer, boolean or int). Errors have three severity levels: 0 for warnings, 1 for errors and 2 for impossibilities. Normally level 0 errors are logged and no error value is returned, i.e. normal processing continues, level 1 and 2 errors are logged and then 'exit' is called. But this is under user control, via the error threshold argument to NSLInit.
If the error threshold is 0, behaviour is as specified above. If it is -1, warnings will cause exits as well. If it is 1, errors will attempt to carry on, returning error values all the way out. If it is 2, the same is true for impossibilities. In other words, when an error is logged, the code after that is effectively:
if( severity > error_threshhold ) exit;
- Table of Contents
- NSLInit — function to initialise LT XML and set level of error reporting.
- NSLGetoptions — process standard options
- NSLInitNames — function to control the behaviour of attribute names.
- NSLClose — function to deallocate resources allocated by NSLInit
NSLInit
Description
This function initialises the LT XML API library. It should be called once before any other LT XML functions are called. It returns TRUE for success or FALSE for failure (probably due to inability to allocate enough space for internal tables). The error_Threshold parameter of NSLInit controls error handling in the NSL interface as described in Error handling.
Usage
This example is a stripped down version of the LT XML tool xmlnorm. The marked line shows the standard use of NSLInit.
#include "nsl.h"
int main(int argc, char **argv){
NSL_Bit *nslbit;
NSL_File sf, outf=0;
NSL_Doctype dct = NULL;
CharacterEncoding enc = CE_unknown;
NSL_FType intype = NSL_read, outtype = NSL_write_normal;
NSLInit(0); (1)
sf = OpenURL(argv[1],dct,intype,enc,NULL);
dct = DoctypeFromFile(sf);
outf = OpenStream(stdout, dct, outtype,enc,"<stdout>");
while( ( nslbit = GetNextBit(sf) )){
if (nslbit->type==NSL_bad) {
PrintText(outf,(Char *) "!\n!!bad bit!!!\n");
return 1;
} else {
PrintBit(outf,nslbit);
}
FreeBit(nslbit);
}
SFrelease(sf,FALSE);
SFrelease(outf,TRUE);
NSLClose();
return 0;
}
- (1)
- Initialise NSL with the default (strict) error reporting
NSLGetoptions
Synopsis
NSL_Common_Options * NSLGetoptions(
int *argcp, char
**argv,
const char *opts,
void (*usage)(int exitval));Description
The string opts contains the standard options applicable to the program. These are
- h
Provide version and usage information
- d
Load main doctype from specified file
- D
Load subsiduary doctype from specified file. Programs such as sgrpg have one doctype for regular input files and other for a subsiduary input file such as a configuration or script file in XML syntax.
- e
Do not expand entities on reading in, or on writing out of XML.
- u
Set the base URL specified by the argument
- V
Extensively validate XML input.
After calling NSLGetoptions argc and argv will have only the non-standard options left.
options = NSLGetoptions(&argc, &argv, "?duz", usage);
NSLInitNames
Description
This function modifies the behaviour of LT XML regarding attribute names. It should not need to be called unless you have existing code which calls the LT XML API, or you want to access attribute values without knowing the doctype of an item.
The type NSL_Name_Behaviour is defined as:
typedef enum { NSL_use_names, NSL_use_strings } NSL_Name_Behaviour ;
For efficiency reasons, we have made attribute names unique names per doctype in the same way as element names. This means that (a) attribute names to GetAttrVal and PutAttrVal must be unique names (i.e. the result of calling AttrUniqueName on the string name of an attribute), and that (b) there is doctype parameter to ParseQuery and ParseQueryR. However, for reasons of backward compatibility, we allow a mode where attribute names can be arbitrary strings, and the doctype parameter to ParseQuery can be NULL. Use of this mode is deprecated.
Usage
This schematic example indicates how to use NSLInitNames.
#include "nsl.h"
int main(int argc, char **argv){
NSLInit(0);
NSLInitNames(NSL_use_strings); (1)
processing_with_string_behaviour();
NSLInitNames(NSL_use_names); (2)
processing_with_name_behaviour();
NSLclose();
return 0;
}- (1)
- The backward compatibility mode is enabled. Strings passed to GetAttrVal and PutAttrVal need not be unique names. The NSL_Doctype argument to ParseQuery and ParseQueryR can be NULL. Comparisons of element names must use Strcmp or equivalent.
- (2)
- The backward compatibility mode is disabled. The more efficient default mode is reinstated. Strings passed to GetAttrVal and PutAttrVal must be unique names obtained from the API. The NSL_Doctype argument to ParseQuery and ParseQueryR may not be NULL.
NSLClose
IV. Opening and closing input and output streams
This section describes the functions for opening and closing input and output streams. These functions exist in new and old flavours, because of the fact that Unicode support requires that certain functions have extra arguments to specify character encodings.
Were we working in a language which permitted default arguments, as C++ and Lisp do, but C does not, we could have avoided the need for extra functions.
- Table of Contents
- OpenURL — function to open a stream to an XML document described by a URL.
- OpenStream — function to create an NSL_File from an existing standard I/O FILE *.
- OpenString — function to open a stream to or from an LT XML string.
- ReadProlog — read document prolog under user control
- SFFopen — function to open a stream to an XML document connected to a C stdio file handle.
- SFopen — function to open a stream to an XML document specified by a file name file handle.
- SFclose — function to close a file opened with SFFopen or similar.
- SFrelease — function to close file, releasing memory and (optionally) NSL_Doctype
OpenURL
Synopsis
NSL_File OpenURL(const char *url,
const NSL_Doctype dtype,
NSL_FType type,
CharacterEncoding encoding,
const char8 *base);Inputs
- url
The URL on which the stream is to be based If url is a relative URL it is combined with the base URL base.
If base is null a default base URL is used, referring to the current directory with scheme file: This allows filenames to be used as URLs. The merged url is stored in the returned NSL_File, and can be retrieved using the function GetFileURL (the main use for this is to provide a base URL when opening URLs referred to in the document).
- base
The base URL, see discussion of url above.
- dtype
can either be an explicitly given XML DTDescription (always needed for output files, and can be used to override the declared DTD of input files), or NULL, in which case the DTD to be used will be read from the file and saved in the return value where it can be found by using DoctypeFromFile
- type
The mode of the stream. In 1.1 this was an enumerated type. For greater flexibility it is now an integer built from the flags specified below. You must always specify exactly one of NSL_read or NSL_write as part of the set of flags used. For backward compatibility some of the flags used in the earlier version (notably NSL_write_normal are given pre-defined meanings which include NSL_write or NSL_read (in particular NSL_write_normal is equivalent to NSL_write). New programs should use NSL_write and NSL_read directly.
The last four flags are provided for convenience and backward compatibility. Even finer grained control of input and output is available by using RXP, at the expense of the convenience features offered by LT XML.File flags
- NSL_read
Read the document. The default behaviour is to expand entity references, to refrain from passing to the application processing instructions, comments and document type information, and to permit some forms of strictly illegal XML (although in the last case warning messages will be produced when the illegalities are encountered).
- NSL_read_all_bits
The library will pass to the application not only content elements but also comments, processing instructions CDATA is marked as such. If you additionally specify NSL_read_no_consume_prolog document type information will also be returned in the form of a bit. This flag is provided primarily for the benefit of applications such as XML structure editors which need to show all aspects of a document.
- NSL_read_strict
Check almost all aspects of the document for conformance with the XML standard. In this mode processing stops when an error is encountered. In practice this mode is mainly for parser debugging, when we run our tools against test suites of pathologically peculiar XML.
- NSL_read_no_expand
Do not expand entity references. This is again useful for editor like applications, where we need to show the whole contents of the source file.
- NSL_read_no_consume_prolog
Don't read the prolog immediately on file opening. Use with NSL_read_all_bits to get the prolog information as bits. This is again useful for editor like applications, where we need to show the whole contents of the source file.
- NSL_no_normalise_attributes
Leave attributes as they were in the file. This is again useful for editor like applications, where we need to show the whole contents of the source file.
- NSL_read_defaulted_attributes
Return default values for attributes if they are not explicitly given, as if they were really there. (Note that the function GetAttrStringVal always returns defaults if appropriate, regardless of this flag.)
- NSL_read_flags
A mask which allows us to pick out read information, as in:
if((type & NSL_read_flags) == (NSL_read_all_bits|NSL_read_strict)) strict_and_exhaustive_activities();- NSL_write
Write the document. By default the LT XML library ensures that doctype information is added to the output document before any content information. By default record ends are added before start tags in element-only content.
- NSL_write_no_doctype
When this flag is specified it switches off the default printing of doctype information.
- NSL_write_plain
This is the same as NSL_write.
- NSL_write_fancy
Specifying this flag ensures that record ends are added at the start and end of the text content.
- NSL_write_canonical
Write canonical XML, as defined by James Clark. Primarily useful for checking the software against pre-existing test suites.
- NSL_write_no_expand
Counterpart of NSL_read_no_expand. Prevents & from being escaped in the output file.
- NSL_write_default
Same as NSL_write.
- NSL_write_style
mask for style information
- NSL_write_flags
mask for write information
- NSL_write_minimal
defined as NSL_write|NSL_write_plain|NSL_write_no_doctype (i.e. print only what is explicitly passed to the stream, adding no extras).
- NSL_write_normal
defined as NSL_write, provided mainly for backward compatibility.
- NSL_write_pretty
defined as NSL_write|NSL_write_fancy.
- NSL_write_normal_nd
defined as NSL_write|NSL_write_no_doctype.
Cautions
Not all URLs are supported
Currently only http: URLs and file: URLs without a host part are supported. Writing is only supported for file: URLs.
You are not supposed to use schemes with relative URLs, i.e. using file:foo.xml to mean a file relative to the base URL. The recommended form is foo.xml. The form with file: will work if the base URL is a file URL (a warning is given), but will not work if the base URL is an http: URL.
In LT XML 1.2 fragment locators (foo:bar#nizz) are not permissible as URLs.
We do not currently handle http redirects.
Pipelines and URLs
You need to be very careful when working with relative URLs in pipelines. Pipelines of tools all of which run in the same directory will give few problems. Pipelines whose tools are distributed across different directories, across machines, or across network locations are likely to give unexpected results. Each tool may have a different working directory, hence it is possible that each tool will find a different interpretation for a particular relative URL.
In the right hands this property of relative URLs could be a powerful feature, but it has clear potential for causing considerable confusion. There are however clear advantages to using relative URLs, since they make it easy for corpora to be moved around a file system without editing the data files themselves.
Most tools now take a -u switch which specifies the base URL against which URLs are interpreted. Systematic use of this switch is advisable in complex pipelines.
Usage
A standard technique for opening an XML file, processing it and writing a copy of it , is as follows.
#include "nsl.h"
int main(int argc, char **argv){
NSL_Bit *nslbit;
NSL_File sf, outf=0;
NSL_Doctype dct = NULL;
CharacterEncoding enc = CE_unknown;
NSL_FType intype = NSL_read, outtype = NSL_write_normal;
NSLInit(0);
sf = OpenURL(argv[1],dct,intype,enc,NULL); (1)
dct = DoctypeFromFile(sf);
outf = OpenStream(stdout, dct, outtype,enc,"<stdout>");
while( ( nslbit = GetNextBit(sf) )){
if (nslbit->type==NSL_bad) {
PrintText(outf,(Char *) "!\n!!bad bit!!!\n");
return 1;
} else {
PrintBit(outf,nslbit);
}
FreeBit(nslbit);
}
SFrelease(sf,FALSE);
SFrelease(outf,TRUE);
NSLClose();
return 0;
}
- (1)
- Open the URL specified on the command line,using the default base URL.
OpenStream
Synopsis
NSL_File OpenStream(const FILE *fp,NSL_Doctype dtype, NSL_FType ftype, CharacterEncoding encoding, const char *name);
Inputs
- fp
The FILE * which identifies the document to be processed.
- dtype
As for OpenURL.
- ftype
As for OpenURL.
- name
The encoding description for this stream.
- name
A string identifying the document, used for error reporting. It may be the name of the input file if this is known, or something like <stdin>. It is also stored as the URL of the document (merged with the default base URL as described under OpenURL); if this is not appropriate the function SetFileURL may be used to change it.
Usage
A standard technique for opening an XML file, processing it and writing a copy of it , is as follows.
#include "nsl.h"
int main(int argc, char **argv){
NSL_Bit *nslbit;
NSL_File sf, outf=0;
NSL_Doctype dct = NULL;
CharacterEncoding enc = CE_unknown;
NSL_FType intype = NSL_read, outtype = NSL_write_normal;
NSLInit(0);
sf = OpenURL(argv[1],dct,intype,enc,NULL); (1)
dct = DoctypeFromFile(sf);
outf = OpenStream(stdout, dct, outtype,enc,"<stdout>");(2)
while( ( nslbit = GetNextBit(sf) )){
if (nslbit->type==NSL_bad) {
PrintText(outf,(Char *) "!\n!!bad bit!!!\n");
return 1;
} else {
PrintBit(outf,nslbit);
}
FreeBit(nslbit);
}
SFrelease(sf,FALSE);
SFrelease(outf,TRUE);
NSLClose();
return 0;
}
- (1)
- Use OpenURL to open a stream from a URL specified on the command line. (In a real program we would check that the command line makes sense before doing this). We specify NULL as the NSL_Doctype argument, and CE_unknown as the character encoding. This means that both document type information and character encoding information are read from the input document and stored in dtype.
- (2)
- Use the doctype of the input file to open an output file on standard output. Because CE_unknown has been specified as the output character encoding, and a non-NULL NSL_Doctype has been provided, the actual encoding used is the one which has been stored in the doctype structure when the input file was opened two lines above.
OpenString
Synopsis
NSL_File OpenString(const char *text, const NSL_Doctype dtype, NSL_FType ftype);
Inputs
- text
The string from which input is taken, or to which output is sent. Note that when LT XML is compiled in 16-bit mode, the Char element type of the string may be (in fact, for most systems, will be) distinct from the char type of conventional C strings.
For output the programmer must ensure that the allocated size string is big enough to contain all the data which will be written there. A future release of LT XML may provide a mode which lifts this restriction.
For input, the string which is passed in must be in LT XML's internal character encoding. OpenString does no character encoding conversion, so it is the programmer's responsibility to ensure that the string is correctly encoded. Typically this will already be the case if the string has been obtained via an LT XML API function. Otherwise, as in the example program below, it necessary to call strdup_char8_to_Char to perform the conversion.
It is processed as if it were the value of an internal entity. This means, in particular, that it should not contain an XML declaration. (If it does, it will still be processed, but a warning message will be printed to standard error).
- dtype
As for OpenURL.
- ftype
As for OpenURL.
Usage
The following example reads from a string and outputs to standard output.
#include "nsl.h"
#include "string16.h"
int main(int argc, char **argv){
NSL_Bit *nslbit;
NSL_File sf, outf=0;
NSL_Doctype dct = NULL;
CharacterEncoding enc = CE_unknown;
NSL_FType intype = NSL_read, outtype = NSL_write_normal;
static char inputString[] = "<!DOCTYPE FILE [\n\
<!ELEMENT FILE (HEADER,TEXT)>\n\
<!ELEMENT HEADER (#PCDATA)>\n\
<!ELEMENT TEXT (P*)>\n\
<!ELEMENT P (W*)>\n\
<!ELEMENT W (#PCDATA)>\n\
<!ATTLIST W TYPE CDATA #REQUIRED>\n\
] >\n\
<FILE>\n\
<HEADER>blah blah</HEADER>\n\
<TEXT>\n\
<P>\n\
<W TYPE='det'>The</W>\n\
<W TYPE='nn'>cat</W>\n\
</P>\n\
</TEXT>\n\
</FILE>";
Char * text;
NSLInit(0);
text = strdup_char8_to_Char(inputString); (1)
sf = OpenString(text,dct,intype); (2)
dct = DoctypeFromFile(sf);
outf = OpenStream(stdout, dct, outtype,enc,"<stdout>");
while( ( nslbit = GetNextBit(sf) )){
if (nslbit->type==NSL_bad) {
PrintText(outf,(Char *) "!\n!!bad bit!!!\n");
return -1;
} else {
PrintBit(outf,nslbit);
}
FreeBit(nslbit);
}
SFrelease(sf,FALSE);
SFrelease(outf,TRUE);
NSLClose();
return 0;
}ReadProlog
Description
This function is only needed in conjunction with the NSL_read_no_consume_prolog flag to the file opening functions. Unless the NSL_read_no_consume_prolog flag is specified, the input functions will autmatically ensure that the necessary information from the prolog is read and recorded.
But if the user specifies NSL_read_no_consume_prolog, this will not happen. On the one hand, it is his responsibility to either call ReadProlog or manually read the prolog bits before calling any functions that require the doctype (eg AttrUniqueName). On the other hand it will be possible for applications such as structure editors to have accurate knowledge of every aspect of the contents of the document.
SFFopen
Description
SFFopen opens a stream which reads from the standard I/O file handle specified. If the name of the file ends in `.gz', then it is treated as a compressed file. If reading, the file will be uncompressed on input. If writing, then the file will be compressed on output.
OpenStream provides similar functionality, but permits the user to specify a character encoding for output. New programs should use OpenStream. Most of the sample programs which we provide still use SFFopen, but will in due course be changed. Don't hold your breath!
Usage
A standard technique for opening an XML file, processing it and writing a modified version of it, can be initialised as follows (see also simple.c and simpleq.c):
#include "nsl.h"
int main(int argc, char **argv){
NSL_Bit *nslbit;
NSL_File sf, outf=0;
NSL_Doctype dct = NULL;
NSL_FType intype = NSL_read, outtype = NSL_write_normal;
NSLInit(0);
sf = SFFopen(stdin,dct,intype,"<stdin>"); (1)
dct = DoctypeFromFile(sf); (2)
outf = SFFopen(stdout, dct, outtype,"<stdout>"); (3)
while( ( nslbit = GetNextBit(sf) )){
if (nslbit->type==NSL_bad) {
PrintText(outf,(Char *) "!\n!!bad bit!!!\n");
return 1;
} else {
PrintBit(outf,nslbit);
}
FreeBit(nslbit);
}
SFclose(sf);
SFclose(outf);
NSLClose();
return 0;
}
Errors
If an error occurs then NULL is returned. Possible errors are:
- NEIFND
No doctype provided for or found in SGML input file.
- NWOFND
XML Output file needs doctype for normal or pretty output but none supplied or defaulted: minimal output will ensue.
SFopen
Synopsis
NSL_File SFopen(const char8 * name,NSL_Doctype dtype,NSL_FType ftype)
Details as for SFFopen but specifying source using a file name rather than a file handle.
Usage
A standard technique for opening an XML file, processing it and writing a modified version of it, can be initialised as follows (see also simple.c and simpleq.c):
char8 * filename; NSL_File inf, outf; NSL_Doctype dct=NULL; ... inf=SFopen(filename, dct, NSL_read); (1) dct=DoctypeFromFile(inf); outf=SFFopen(stdout, dct, NSL_write_normal,""); (2)
See also
OpenURL, which was new in 1.1, provides similar functionality, and supports input from URLs. SFopen also allows input from URLs, but OpenURL allows a character encoding and a base URL to be provided. New programs should use OpenURL.
SFclose
Description
Close the NSL_File f. This should be done explicitly for every output file opened by your program.
If memory usage is a concern (as it will be for long-running programs and when working on platforms with primitive or absent virtual memory facilities), you may prefer to use SFrelease, which will automagically free the resources associated with the processing of the corresponding file when the releaseDoctype argument is true.
Usage
The following is a stripped down version of the xmlnorm tool which is part of LT XML. The marked lines show the usage of SFclose.
#include "nsl.h"
int main(int argc, char **argv){
NSL_Bit *nslbit;
NSL_File sf, outf=0;
NSL_Doctype dct = NULL;
CharacterEncoding enc = CE_unknown;
NSL_FType intype = NSL_read, outtype = NSL_write_normal;
NSLInit(0);
sf = OpenStream(stdin,dct,intype,enc,"<stdin>");
dct = DoctypeFromFile(sf);
outf = OpenStream(stdout, dct, outtype,enc,"<stdout>");
while( ( nslbit = GetNextBit(sf) )){
if (nslbit->type==NSL_bad) {
PrintText(outf,(Char *) "!\n!!bad bit!!!\n");
return 1;
} else {
PrintBit(outf,nslbit);
}
FreeBit(nslbit);
}
SFclose(sf); (1)
SFclose(outf); (2)
return 0;
}
SFrelease
Description
Similar to SFclose, but cleans up all memory allocated by SFopen on the heap and in virtual memory. This is not the default, because once you have called SFrelease, you are no longer allowed to access any XML structure which you read from that file, i.e. NSL_Items, NSL_Bits or NSL_Datas or strings from them. If you access such pointers after SFrelease, unpredictable errors or other odd behaviour is almost guaranteed.
If your application is speed critical, and you don't care about memory leaks, then you may wish to avoid SFrelease, since it is more costly than SFclose. On the other hand, if you are opening, processing and closing many files independently of each other, then memory usage will be easier to keep track of if you systematically prefer SFrelease
If the releaseDoctype parameter is TRUE, then the space allocated to the NSL_Doctype is freed. If FALSE, then the NSL_Doctype is not freed.
If TRUE is specified as the second parameter, the programmer must ensure that the NSL_Doctype associated with the document is one on which the library can safely call free, and must also ensure that no subsequent use is made of other files which refer to the same doctype. In particular, this means that when you are writing a simple filter, you should ensure that the second parameter to SFrelease is TRUE only when closing the second of the two files involved. This is shown in the usage example.
Usage
The following is a stripped down version of the xmlnorm tool which is part of LT XML. The marked lines show the usage of SFrelease.
#include "nsl.h"
int main(int argc, char **argv){
NSL_Bit *nslbit;
NSL_File sf, outf=0;
NSL_Doctype dct = NULL;
CharacterEncoding enc = CE_unknown;
NSL_FType intype = NSL_read, outtype = NSL_write_normal;
NSLInit(0);
sf = OpenStream(stdin,dct,intype,enc,"<stdin>");
dct = DoctypeFromFile(sf);
outf = OpenStream(stdout, dct, outtype,enc,"<stdout>");
while( ( nslbit = GetNextBit(sf) )){
if (nslbit->type==NSL_bad) {
PrintText(outf,(Char *) "!\n!!bad bit!!!\n");
SFrelease(sf,FALSE);
SFrelease(outf,TRUE);
return 1;
} else {
PrintBit(outf,nslbit);
}
FreeBit(nslbit);
}
SFrelease(sf,FALSE); (1)
SFrelease(outf,TRUE); (2)
return 0;
}
V. Document type information
This section describes functions for getting information about the elements and attributes of a document type definition which is present in a disk file. These files are either .ddb files generated by LT NSL or simply XML documents which happen to be stored in files.
- Table of Contents
- LoadDoctype — load document type from file.
- DoctypeFromDdb — function to read a description of an XML DTD which is contained in the .ddb file given by the file name filename.
- DoctypeFromFile — function to read a description of an XML DTD which is contained in the XML file given by the file name filename.
LoadDoctype
Description
A new function has been added. It reads the doctype from the file, either by calling DoctypeFromDdb (if the filename ends .ddb) or by opening the file as an input file, and returning the resulting doctype. In LT XML 1.2 the -d flag passed to standard applications has been changed to use this function, so that the applications can now be given alternate doctypes to use with XML files.
This function means that DoctypeFromDdb should probably be removed from the API, except that the latter does not require that that DDB files have a .ddb extension.
DoctypeFromDdb
Name
DoctypeFromDdb -- function to read a description of an XML DTD which is contained in the .ddb file given by the file name filename.Caveat
| Warning |
The base distribution of LT XML 1.2 does not include tools for generating .ddb files, although it is able to process them. The next version of LT NSL will be packaged as an add-on, which enhances LT XML with additional tools based on James Clark's SP. This will provide continued support of .ddb files for users of LT NSL. In any case, it is preferable to use LoadDoctype, which also handles XML files. |
DoctypeFromFile
VI. File positioning
SFseek
Description
The seek pointer associated with file is set to pos bytes into the file. The return value is pos, or -1 on error. Not surprisingly, an error is signalled, if the input file which the NSL_File is based on is compressed, or if the FILE* in question corresponds to a socket or a pipe.
SFtell
VII. URL Utilities
- Table of Contents
- GetFileURL — function that returns the URL associated with file.
- SetFileURL — function that sets the base URL associated with a file
- url_merge — function to fill in default information in a target URL by merging it with a base URL. The target information takes precedence.
GetFileURL
Description
Returns the URL associated with file. This URL is typically used as the base for URLs referred to in the document.
SetFileURL
Description
Sets the URL associated with file to be url. This is useful in conjunction with OpenStream and OpenString. and in cases where the intended effective URL of the file is different from the effective URL with which it was opened.
url_merge
Name
url_merge -- function to fill in default information in a target URL by merging it with a base URL. The target information takes precedence.VIII. Reading SGML
There are two methods of reading XML files. The first is to use GetNextBit or GetNextItem which are described below. The other is to use the LT XML query facilities which are described in the next section.
- Table of Contents
- GetNextBit — function that returns the next NSL_Bit on a stream
- GetNextItem — function that returns the next NSL_Item on a stream
- ItemParse — function that fills in an NSL_Item of type NSL_inchoate
GetNextBit
Description
Read and return the next NSL_Bit from the NSL_File, which must be open for reading. The NSL_Bit returned is an API-internal constant, so its contents will not be preserved from one call to the next. NULL is returned at end of file.
GetNextItem
Description
Read and return the next NSL_Item from sgmlfile. If the current position in the file is before an SGML start tag, the entire contents of this element is returned. If before an SGML empty tag, then this is returned. NULL is returned at end of file. Processing instructions are ignored and the next element read and returned. It is an error if the current file position is not before SGML markup, i.e. before text or a close tag.
It is possible to mix calls to GetNextItem with calls to GetNextBit on the same file, as long as you know that you are positioned before a start tag before calling GetNextItem. In practise, you often do not know this until you have already read the start bit. The following function lets you read the rest of the item once you have read its start bit.
ItemParse
Description
Given an NSL_Item of type NSL_inchoate, (i.e. one which only refers to an SGML start tag), read the SGML file sgmlfile (up to the matching end tag) and fill in the contents of this NSL_Item.
Usage
The fragment below, shows how one might handle the case where you are reading bits and want to change to reading items.
/* reading bits */
bit = GetNextBit(file);
if( bit->type == NSL_start_bit ){
item = ItemParse(file,bit->value.item); /* reads this item, including its subitems */
... /* now read some subsequent items */
}IX. Queries
- Table of Contents
- ParseQuery — function to convert a query to internal form
- ParseQueryR — convert a query to internal form, allowing regular expressions as value of attributes
- ParseQuery8 — convert an 8-bit query to internal form
- ParseQueryR8 — convert an 8-bit query to internal form, allowing regular expressions as value of attributes
- GetNextQueryItem — function that fetches the next item matching a query, optionally printing non-matching content as it is read
- RetrieveQueryItem — function that searches an in-memory item for matches to a query
- RetrieveQueryData — retrieve NSL_Datas which match a query
ParseQuery
Description
This function takes a string containing a query and converts it into an internal form which can be used as a argument to GetNextQueryItem or RetrieveQueryItem. A query is a pattern which defines which SGML elements to select. Note that qu is const and can be freed ad lib, as ParseQuery makes a private internal copy of the parts it holds on to.
ParseQueryR
Name
ParseQueryR -- convert a query to internal form, allowing regular expressions as value of attributesDescription
This function is similar to ParseQuery but its query may contain regular expressions for the values of attributes. Regular expressions are handled by Henry Spenser's implementation (see regexp(3) for documentation). A version of this regexp package is included in the LT XML library.
ParseQuery8
Description
This function is similar to ParseQuery but its query is an 8-bit string even when the system is compiled in 16-bit mode.
ParseQueryR8
Name
ParseQueryR8 -- convert an 8-bit query to internal form, allowing regular expressions as value of attributesDescription
This function is similar to ParseQueryR but its query is an 8-bit string even when the system is compiled in 16-bit mode.
GetNextQueryItem
Name
GetNextQueryItem -- function that fetches the next item matching a query, optionally printing non-matching content as it is readDescription
Given am XML document infile (open for reading) and a NSL_Query query return the next complete SGML element which matches this query as an NSL_Item. Parts of the input document which occur between the present position and the matching item are written to the ofile output document. If ofile is NULL then input which does not match the query is read and discarded. Subsequent calls to GetNextQueryItem return subsequent matches. In nested elements (for example <P> inside <P>) only the outer element is returned. GetNextQueryItem returns a pointer to the matching item or NULL if end of file was reached.
Usage
A standard paradigm for using GetNextQueryItem is thus:
while( ( item=GetNextQueryItem(infile, query, outfile ) ) ) {
process_item(item);
PrintItem(outfile, item);
FreeItem(item);
}where process_item is your code that modifies item}.
RetrieveQueryItem
Description
This function does a depth first search of uitem to find all items inside it which match the query query. On the first call, from should be NULL. On subsequent calls, if from is set to the previous match (return value) then subsequent matches will be returned. NULL is returned if there are no (more) matches.
Usage
An example of its use:
subitem = NULL;
while( subitem = RetrieveQueryItem(item, query, subitem) ){
/* Do something with subitem */
}RetrieveQueryData
Synopsis
boolean RetrieveQueryData( NSL_Item *uitem, NSL_Query query , const NSL_Data **fromRet, boolean noText );
Description
A new function in LT XML 1.2, This function is similar in spirit to RetrieveQueryItem. However, it returns the NSL_data structure which contains the matching item (in the fromRet parameter) and it returns TRUE/FALSE depending on whether a matching data was found or not. This means it can be used to find particular bits of text content, rather than only SGML elements. If however, noText is TRUE, then we only return NSL_Data which contain an NSL_Item.
Note: Unlike RetrieveQueryItem, the fromRet parameter should not be NULL, it must be a non-NULL pointer to a pointer to an NSL_Data, which should be NULL on the first call.
X. Printing
The following functions can be used to write to NSL_File outputs. Writing to NSL_Files using printf or other such functions is not recommended since that could result in the generation of invalid SGML.
Here be lions: PrintText prints #PCDATA -- any '&' or '<' characters in the text will be taken to stand for the characters themselves, and printed using appropriate escapes in order to ensure that the next XML processor in the pipeline does not think that they mark SGML structure. Thus the use of PrintText is not an effective means of adding extra SGML structure to an output file.
If you want to do this, perhaps in order to cage dangerous lions inside a vulnerable larger structure, to one possibility is to use GetItemFromString as follows:
static char buffer[SIZE_FOR_A_LARGE_LION_PLUS_14]; sprintf(mystring,"<cage>%s</cage>",wild_animal_string); item=GetItemFromString(mystring,doctype); PrintItem(file,item); FreeItem(item);If the lion was a well-formed XML string and your guess about the buffer size was sufficiently conservative, nobody will get eaten.
Note: Another possibility is to use PrintTextLiteral, which does not expand putative markup in the provided text.
- Table of Contents
- PrintBit — Print a single bit.
- PrintStartTag — print the start-tag of a new item
- PrintItemStartTag — print the start tag of an existing item
- PrintEndTag — print the end-tag on an item
- PrintItem — Print an item.
- PrintText — Print text
- PrintTextLiteral — Print text literally with no expansion of markup.
- ForceNewline — ensure that a newline is put to the output file
- ForceOutput — flush output to an SGML stream
PrintBit
PrintStartTag
Description
Equivalent to PrintBit on an item of type NSL_start_bit. Label is the name of the SGML element which is being opened.
This function does not allow for the specification of attributes on the start tag, so its usefulness is limited.
PrintItemStartTag
PrintEndTag
Description
Equivalent to PrintBit on an item of type NSL_end_bit. Label is the name of the SGML element which is being closed.
Obviously, if you do this, you are taking on the responsibility for ensuring that everything is balanced
PrintItem
PrintText
PrintTextLiteral
ForceNewline
Description
Writes a newline to the output stream NSL_File, but taking account of XML state and printing mode.
ForceOutput
XI. Attributes
- Table of Contents
- GetAttrStringVal — Get the value of an attribute
- GetAttrVal — get the value of an attribute.
- GetAttrSVal — get an explicitly present attribute value
- PutAttrVal — set an attribute value
- GetIDVal — get the value of the ID attribute on an item
- GetItemFromString — read an item from a string
GetAttrStringVal
Description
Return the value of attribute name associated with the NSL_Item item as a string (0-terminated Char sequence). Defaulted as well as explicitly given attributes can be accessed using this function. Default values (defined in the DTD) will be returned if there is no explicit attribute value given on the SGML element represented by the item. There is no direct way to tell if you are getting explicit or default values. In the case that there is no proper default value given in the DTD, i.e. if the attribute's default value specification is #IMPLIED or #CONREF, and there is no explicit value, then GetAttrStringValreturns a pointer to the constant empty string NSL_Implied_Attribute_Value.
Usage
Thus a safe way of calling this function is
if( ( tagVal = GetAttrStringVal(item,attrName))){
if( tagVal == NSL_Implied_Attribute_Value){
/* No value given, it is up to the application */
/* to decide on a value */
} else {
/* Attribute value defined. NB it may be an empty string */
}
} else {
/* An error - probably attrName is not defined for this item */
}
This function returns NULL on error.
GetAttrVal
Description
Return the value of attribute name associated with the NSL_Item item as an untyped pointer. Defaulted as well as explicitly given attributes can be accessed using this function. Return values are as for GetAttrStringVal. In the present release, this function is the same at GetAttrStringVal.
In future, it is possible that we will introduce typed attributes, in which case this function will return a pointer to the typed value of the attribute, (for example a pointer to an int if the attribute is of type NSL_attr_num).
GetAttrSVal
Description
If no value is explicitly present on the item, no processing is undertaken to recover default information from the DTD, and NULL is returned.
PutAttrVal
Description
This function changes an existing attribute if present, adds a new one otherwise, and returns an integer as follows: -1 on error, 0 if changed an existing attribute, 1 if made a new one. It does not free the old value if there was one.
There is one subtlety to this: if one sets a #CONREF attribute to an explicit value with this function, then the item will be marked as type NSL_empty.
GetIDVal
Description
This function returns the value of the attribute of item which is of type ID. If the item has no attribute of this type, then NULL is returned. The point of this function is that since an SGML element can have at most one ID attribute, one need not know the name of this attribute in order to find an element's identifier.
GetItemFromString
Description
Read a single NSL_Item from the C string text. This function provides a simple way of constructing a piece of SGML structure within a program. For example:
item = GetItemFromString("<name>David<surname>McKelvie</surname></name>",dct);will construct the data structure shown in Figure 1.
If there is more than one toplevel SGML element in the string, then only the first complete element is returned. If the string does not start with an element then NULL is returned. dtype should be a concrete NSL_Doctype data structure obtained via DoctypeFromFile or something similar.
XII. Creating LT XML data structures
There are two means of creating LT XML data structures: from strings (using GetItemFromString) and via explicit API manipulations, using a raft of other functions.
- Table of Contents
- NewNullNSLData — Create a new empty NSL_Data structure.
- NewNullNSLItem — create a new item
- NewTextNSLData — create a new NSL_Data containing some text
- NewItemNSLData — Creates a new empty Item
NewNullNSLData
NewNullNSLItem
Description
Create a new NSL_Item (with type set to NSL_inchoate) which refers to an SGML element with name name, as defined in the DTD described by doctype. Len is the length of the name (if it is zero, then NewNullNSLItem will calculate the length of the name. Returns NULL if no doctype is specified. If no element called name is specified in the DTD, then an NSL_Item will be created with a NULL defn field and a warning message will be printed.
NewTextNSLData
Synopsis
NSL_Data *NewTextNSLData( const NSL_Doctype doctype, const Char *text, int len, boolean copy, const NSL_Data *nextptr, boolean insert);
Description
Creates a new NSL_Data containing the given text. If copy is true, then the string data will be copied into the new NSL_Data, otherwise the string will be pointed to. The next pointer of the new NSL_Data will be set to nextptr. If nextptr is not NULL then the new NSL_Data's in pointer will point to the in pointer of nextptr. If in addition insert is true then the new data will be installed as the first data element of the parent node of nextptr. If insert is true, then nextptr should not be NULL, which means that you cannot use this function to add a new NSL_Data to an NSL_Item which has got no NSL_Data under it already.
Usage
What this all means is as follows. Given an NSL_Item item, the following code will add the text ``Some text'' as the first chunk of the content of this item.
NewTextNSLData("Some text", 0, TRUE, item->data,TRUE);Given an NSL_Data data, the following code will insert the string ``Some text'' after the data, ensuring that all pointers are updated correctly.
new_data = NewTextNSLData("Some text", 0, TRUE, data->next,FALSE);
if( data->next == NULL ){
new_data->in = data->in;
}
data->next = new_data;NewItemNSLData
Synopsis
NSL_Item *NewItemNSLData(NSL_Doctype doctype,
const char * name,
int len, const NSL_Data *nextptr, boolean insert);Description
Similar to NewTextNSLData. Creates a new empty Item with name name, len is the length of name or 0 if the length is unknown. Make the new Item the 'first' of a new Data. Give that Data nextptr for its 'next' field. If nextptr is non-NULL, copy its 'in' field to the new Data's 'in' and, if insert is true, make the new Data be 'first' of its 'in', i.e. insert the new Data at the head of the Data chain.
XIII. Copying LT XML structures
These functions copy information obtained from the API, in order that modifications can be made without affecting the originals.
We have ceased to document the confusing CopyBit, since it does not allocate heap memory, and is equivalent to a C structure assignment operation. It should not be used. We'll leave it in for now, just in case it makes life easier for you.
NSL_Bit bit1,bit2; bit1 = bit2;
CopyData
Description
This function makes a copy of the NSL_Data structure data and returns the copy. The new NSL_Data will be placed inside item, (i.e. its in pointer will point at item). This operation is a recursive tree walk, not a shallow copy. Copies will be made of all strings and all NSL_Items encountered. If the structure copied is large, the memory expenditure involved may be substantial.
CopyItem
XIV. Structure navigation and Modification
- Table of Contents
- AddItemToEnd — Add an item after the existing daughters
- MoveDataTail — Move the data after a given location to a new location.
- InstallDataTail — Move an NSL_Data and its successors to a new location.
- InstallData — function to move the successors of an NSL_Data to a new location.
- LinkItem — create a data to hold an item, and link latter into place as child of an element
- LinkText — like LinkItem but for text data
- AddPCData — Add text below an item
- NextDFSNoChildren — Return the first piece of "real content" after a data.
- ObtainItem — find an NSL_Item within an NSL_Data
- ParentItem — Find the parent item of an item
- GetPCDataBelow — return first piece of text data below an item
AddItemToEnd
Description
This function adds the item titem after all existing daughters of item. Item can be empty. It returns the new NSL_Data that was created to hold titem.
MoveDataTail
Description
Move the chain of NSL_Datas occuring after whereFrom to after whereTo, i.e. whereTo->next = whereFrom->next;. The data.in pointers of the moved datas are changed to point to the in pointer of whereTo. whereFrom itself is not moved, but all its successors in the chain are.
InstallDataTail
Description
Add the chain of NSL_Datas newTail after whereTo (i.e. set whereTo's next pointer to newTail), setting their in pointers to the correct place. In contrast to MoveDataTail, newTail itself is moved by this function.
InstallData
Description
Add data as first NSL_Data of item and set in pointers of this chain to be item. If data is NULL, will render item empty, by setting its type to NSL_empty.
Note: The original value in item's data pointer is overwritten: if you need the original for any purpose, for example to ensure that it is correctly freed, you must have saved the value before you call InstallData
LinkItem
Description
This function creates a new NSL_Data which contains the item and links the data after the given data dptr. Returns a pointer to the new data. Changed in release 1.2 to have a doctype argument.
LinkText
Description
This function creates a new NSL_Data which contains the text pointer and links the data after the given data dptr. Returns a pointer to the new data.
Note: N.B. Previously, this function copied the text pointer, but this made tree manipulation code more complex and so was removed.
AddPCData
Synopsis
NSL_Item * AddPCdata( NSL_Item *uitem,
NSL_Doctype doctype,
const Char *pcdata, const Char *path );Description
Given an NSL_Item uitem and a string query path which describes a location of an element relative to uitem, we add pcdata at this location. If an item is not found which matches this query, then an item with the name of the last element in path is created, then intermediate structure leading to that item is constructed as needed.
Note: The path given by the programmer must be expressed in the subset of the query language syntax which does not include wildcards "." or iteration "*". If you violate this constraint the behaviour of the system is undefined.
The pcdata is then added to the matching item as the last data daughter. In order to correctly process the query we need the document type of the SGML tree being edited, this is given by the doctype parameter.
NextDFSNoChildren
Description
Given an NSL_Data return the next NSL_Data. The returned NSL_Data corresponds to the next SGML element or piece of text content occuring textually after data in the document. However, this function does not read from a file, i.e. This is purely a tree-traversal function. If no next data is found NULL is returned. If noText is TRUE, then only datas which contain an NSL_Item are returned, ie text content is skipped until we find the next SGML element.
The name for this function is not very good. It returns next data which appears after data and the contents of data in a top-down left-to-right traversal of the tree. By analogy with what a common function provided by symbolic debuggers it could be called StepOut.
ObtainItem
Description
This function returns a pointer to the first NSL_Item having the label (element name) itemname which is contained in the NSL_Data data . Len is the length of the element name. NULL is returned if no such NSL_Item is found.
This function was called ObtainData in a previous release, which was confusing, as it didn't return a data.
ParentItem
Description
Given a pointer to a NSL_Item, item, this function returns the NSL_Item which contains it, or NULL if it is not contained in any. It follows the in chain of pointers twice, in terms of Figure Figure 1 the ParentItem of the <surname> item is the <name> item.
GetPCDataBelow
XV. Freeing LT XML data structures
The following functions will reclaim space used by LT XML data structures of various kinds. It is the responsibility of the programmer to free structures which are no longer needed, garbage collection is not supported. The following functions are recursive however, in that they free the other data structures pointed to by the structures explicitly freed, this includes the character data and attribute values of the freed element. You can free NSL_Items and NSL_Datas twice without ill effects (the second free being a no-op, although an warning message will be written to stderr). Freeing any of the others twice will have undefined and probably catastrophic effects. All functions return TRUE for success and FALSE for failure.
- Table of Contents
- FreeBit — release memory associated with the item that a bit contains.
- FreeData — Free the data.
- FreeDoctype — Free the space occupied by a NSL_Doctype
- FreeItem — free an item and its contents
- FreeQuery — free a query
FreeBit
Description
Note: Note that this function does not free the bit, it frees the item (if any) to which the bit refers. You need to do this in the (common) case that you are working with the event level interface (via GetNextBit), in which case NSL_Items will have been created for bits of type NSL_start_bit and NSL_empty_bit. The presence of this pointer from bits to items is what makes possible the amphibious switching between the event level and the item level in ItemParse.
FreeData
FreeDoctype
Description
Note: Once you have called this function, then you should not use any items, bits, or datas, or NSL files that refer to this doctype. SFclose is one of the many functions which do use this data, so to be safe you should never close a file after you have freed its doctype. The idiom has to be
dct = DoctypeFromFile(file); SFclose(file); FreeDoctype(dct);You are probably better off calling SFrelease in any case.
FreeItem
FreeQuery
XVI. Accessing the DTD
The following functions are designed to allow a program to find out (some of) the structure of the DTD. This structure is the list of valid element names, the attributes associated to the elements, and the list of defined entities and their values.
Since XML does not require that a document have a DOCTYPE declaration, we do not necessarily enforce the invariants specified by the DTD even when it is present. The level of enforcement is (to a degree) under user control. The following functions can only return the information about the elements which is known at the time of the call. It is unwise to blindly rely on the results of calls made early in the processing of document, since it may be that new information may have been discovered in subsequent processing.
- Table of Contents
- DocumentIsNSGML — determine mode of document
- ElementContent — Return a (string) representation of the content model for an element.
- FindElementByName — element summary from name
- FindElementAndName — element summary from non-unique name
- ElementAttributes — return the attribute descriptions of an element summary
- FindAttrSpec — obtain summary of an attribute
- FindAttrSumAndName — obtain information about attribute of an element
- ElementExists — find out whether it does
- AttrExists — find out whether it does
- GetAttrDefVal — Get the default value for an attribute.
- GetAttrDeclaredValue — Get the declared value from an attribute summary.
- NewAttrVal — add attribute and value to item
- GetAttrDefaultValueType — Get default value type of an attribute
- AttributeName — return the attribute name
- GetAttrAllowedValues — find the allowed values for an attribute
- GetEntity — summary information about an entity.
- GetEntityValue — Get the value of an entity (as string)
- GetEntityDataType — Obtain a value to indicate the nature of an entity.
DocumentIsNSGML
Description
User-level predicate for determining whether a document is being processed in XML mode or nSGML mode.
Note: Documents can be in nSGML mode or XML mode, depending on whether they acquire their information about document type from a .ddb file or by reading the XML <!DOCTYPE... statement. The mode of a document is determined dynamically by the parser as it reads the initial part of the document. In order to conform to the PR-xml-970128 it is necessary to assume that in the absence of information to the contrary we are dealing with XML. The fine detail of output formatting for XML and nSGML differs, so certain applications may need this information.
ElementContent
Synopsis
NSL_Element_Content ElementContent(NSL_Doctype doctype, NSL_ElementSummary eltsum, const Char **model);
Description
This function returns a representation of the content model of the element in question. The return value is an enumeration, one of:
NSL_Content_mixed, NSL_Content_any, NSL_Content_cdata,
NSL_Content_rcdata, NSL_Content_empty, NSL_Content_element
NSL_Content_cdata and rcdata won't be returned for XML, since that content model is not allowed . For mixed and element content, if model is non-null the content model string is stored in it (XML only; since for nSGML we don't have the information). This function is likely to change, because future versions of the system will more thoroughly parse the string representing the content model, returning a more structured representation of the same.
The string returned in model belongs to the library, and will get freed automatically when you free the corresponding NSL_Doctype.
Usage
NSL_ElementSummary sum;
NSL_Element_Content type;
const Char *content = 0;
sum = FindElementByName(dct, tag);
type = ElementContent(dct, sum, &content);FindElementByName
Description
Given a Doctype and an SGML element name, return a summary of the properties of the element. Presently, NSL_ElementSummary structures are mainly used as a parameter to the other functions.
Note: elementname should be a unique name, if not either use ElementUniqueName to get a unique name or use FindElementAndName. If you are using the deprecated backward-compatibility mode which does not use unique names, this note can be ignored.
FindElementAndName
Description
Given a name of an SGML element and len (giving its length), return an NSL_ElementSummary describing the element definition in the DTD. Name is also overwritten with a unique string name for this element as defined in the DTD described by doctype.
The name which you provide must be upper-case if the document being read is nSGML, can be mixed-case for XML
ElementAttributes
Synopsis
NSL_AttributeSummary *ElementAttributes(
NSL_ElementSummary eltsum,const NSL_Doctype
doctype, int * numAttr );Description
Given an element summary return a pointer to an array of attribute summaries for all the attributes defined for this element. The number of attributes is returned via the numAttr parameter. The array is allocated by malloc and it is the users responsibility to free it after use (say by calling free()).
Usage
The following example code shows how one might do some processing on all attributes defined for an SGML element.
NSL_Item *item;
NSL_AttributeSummary *as;
int numAttr;
char * attrName;
as = ElementAttributes(item->defn,&numAttr);
for( i=0; i< numAttr; i++){
attrName = AttributeName(as[i]);
process(attrName);
}
free(as);FindAttrSpec
Description
Given an element summary and an attribute name, return a summary of the definition of the attributes defined for that element.
FindAttrSumAndName
Synopsis
NSL_AttributeSummary
FindAttrSumAndName( NSL_Doctype doctype,
NSL_ElementSummary *eltptr, const char **name, int len);Description
Given a name of an SGML attribute, len (giving its length) and elts an element summary, return the NSL_AttributeSummary describing the attribute definition associated with that elemnt in the DTD. Name is also overwritten with a unique string name for this attribute as defined in the DTD described by doctype. For nSGML name must be upper case.
Note that in the case of XML documents, calling this function with a previously unknown attribute will modify both doctype and elts to incorporate a default (CDATA #IMPLIED) declaration. In this case, eltptr is updated to point to the new definition. }
ElementExists
Description
With arguments similar to those of ElementUniqueName, simply determine if name is known as an element name in doctype.
AttrExists
Synopsis
boolean AttrExists(const NSL_Doctype doctype, const Char*name, int length, NSL_ElementSummary elts);
Description
With arguments similar to those of FindAttrSumAndName, simply determine if name is known as an attribute name from elts in doctype. If elts is NULL, returns true if name is known as an attribute name from any element.
GetAttrDefVal
Description
Given an attribute summary, return the default value of this attribute. If there is no default value defined in the DTD (e.g. for #REQUIRED, #IMPLIED or #CONREF attributes), it returns a pointer to the constant Char *NSL_Implied_Attribute_Value.
Note the return value is not a copy, and therefore should not be subsequently freed.
GetAttrDeclaredValue
Description
Returns the 'declared value' of an attribute, i.e. the type of allowed values of this attribute. Possible values are as in the following enumeration type (semantics as per the SGML documentation):
typedef enum{ NSL_Dec_cdata, NSL_Dec_name, NSL_Dec_number,
NSL_Dec_nmtoken, NSL_Dec_nutoken, NSL_Dec_entity,
NSL_Dec_idref, NSL_Dec_names, NSL_Dec_numbers,
NSL_Dec_nmtokens, NSL_Dec_nutokens, NSL_Dec_entities,
NSL_Dec_idrefs, NSL_Dec_id, NSL_Dec_notation,
NSL_Dec_nameTokenGroup } NSL_Attr_Dec_Value;NewAttrVal
Note
Note that the attribute must already be known to occur on elements of the type of item, i.e. must either have been declared in the DTD or have already occured in input from the file item came from. Use DeclareAttr to add new attributes to an element type.
GetAttrDefaultValueType
Description
Returns the 'default value type' of an attribute as per the DTD. Possible values are as described in the following enumeration type:
typedef enum {NSL_defval_optional, NSL_defval_implied,
NSL_defval_current, NSL_defval_required,
NSL_defval_value, NSL_defval_conref} NSL_ADefType;
where NSL_defval_optional is when an explicit default value has been
given in the DTD, NSL_defval_implied corresponds to
#IMPLIED, NSL_defval_current corresponds to
#CURRENT, NSL_defval_required corresponds to
#REQUIRED, NSL_defval_value corresponds to
#FIXED, and NSL_defval_conref corresponds to
#CONREF.AttributeName
GetAttrAllowedValues
Description
Given an attribute summary and an element summary, return a pointer to the possible allowed values of this attribute. This is only the case if the attribute is an enumeration type attribute or a notation attribute, i.e.if GetAttrDeclaredValue(atsum) is NSL_Dec_nameTokenGroup or NSL_Dec_notation. Otherwise the return value of this function is NULL. The parameter numVals is set to the number of allowed values. If the return value is not NULL, then it is a pointer to an array of string pointers (each '\0' terminated). The end of the array of string pointers is signalled by a single null pointer.
GetEntity
GetEntityValue
Description
Returns the string value of the entity, as a null terminated array of Char.
There is no function to return all entities defined in the DTD, one could be added if there is demand for it.
GetEntityDataType
XVII. Other functions
For efficiency reasons, LT XML uses constant string pointers for all element names and attribute names. These names are unique to one doctype. ElementUniqueName and AttrUniqueName find the unique name given a string. This usually arises when the string has been obtained by reading an SGML document, in which case it will have elements of type Char. ElementUniqueName8 and AttrUniqueName8 find the unique name given an 8-bit string. This usual arises when strings are passed in from the command line or specified as string literals in the program.
- Table of Contents
- ElementUniqueName — get the unique name of an element.
- ElementUniqueName8 — get the unique name of an element.
- AttrUniqueName — unique name for attribute
- AttrUniqueName8 — unique name for attribute
- ParseRCData —
- CurrentBitOffset — offset of current bit (for indexing)
- CurrentItemOffset — offset of current item (for indexing)
ElementUniqueName
Description
Given a name of an SGML element and length (giving its length, if length is 0 the length of the string will be calculated), return a unique string name for this element as defined in the DTD described by doctype. This unique name can then be used for comparison with the label field of NSL_Items by using the C operator == For nSGML; the name must be upper case.
ElementUniqueName8
AttrUniqueName
Description
Given a name} of an SGML attribute and length (giving its length, if length is 0 the length of the string will be calculated), return a unique string name for this attribute as defined in the DTD described by doctype}. This unique name can then be used for comparison with the attribute names found inside NSL_Items by using the C operator ==. The name must be upper case.
Note: The unique name associated with an attribute is only unique relative to an NSL_Doctype. In particular, if one opens an SGML file without specifiying a concrete NSL_Doctype, then a new NSL_Doctype is initialised. Two different files opened in this way will have different "unique names" even for identical attributes. You will even get different names if you open the same file twice, unless you take explicit steps to ensure that the same NSL_Doctype data structure is used in each case.
AttrUniqueName8
ParseRCData
Synopsis
const Char * ParseRCData( NSL_Doctype doctype,
const Char *rcdata,
const Char *(*expandSData)(NSL_Doctype,const Char *));Description
Given a string rcdata, ParseRCData returns a new string in which all SDATA entity references and numerical character references in rcdata have been expanded. This activity makes little sense unless you are processing normalized SGML,for the very good reason that there aren't any SDATA entities in XML: the XML standard doesn't allow them. So XML this function is (nearly) a no-op.It copies the string, but doesn't do any expansion. For this, we need to know the SGML document type (doctype). The expandSData parameter is a function (of signature ( NSL_Doctype doctype, Char *) returning Char*), which is called with the value of each such expanded entity. The value returned by this function is the string interpolated into the result of ParseRCData. Thus, the default expandSData function, which just returns the SGML defined entity value would be:
Char * expandSData( NSL_Doctype, doctype Char * char) {
return char;
}By default, LT XML does not expand SDATA entities or numerical character references. Note that passing the output of ParseRCData to PrintText is potentially dangerous, as PrintText does no inverse processing, so the result may be invalid XML
CurrentBitOffset
Description
Returns the character offset in the input XML file of the start of the last NSL_Bit read from it.Used to implement indexing schemes.
CurrentItemOffset
XVIII. Manipulating Attributes
Attributes attached to SGML start tags are described by a linked list of NSL_attr data structures attached to the NSL_Item.
typedef enum {NSL_attr_num, NSL_attr_nums, NSL_attr_id,
NSL_attr_refid, NSL_attr_refids, NSL_attr_string,
NSL_attr_entity, NSL_attr_entities, NSL_attr_float,
NSL_attr_token, NSL_attr_tokens, NSL_attr_notation} NSL_AVType;
typedef enum {NSL_defval_optional, NSL_defval_implied, NSL_defval_current,
NSL_defval_required, NSL_defval_value, NSL_defval_conref} NSL_ADefType;
typedef struct NSL_Attr {
NSL_AVType valuetype; /* type of value */
NSL_ADefType deft; /* type of default value */
const char *name; /* name of attribute */
union {
const Char *string; /* NAME, STRING */
} value; /* actual value */
struct NSL_Attr *next; /* list link */
} NSL_Attr;The valuetype field describes the type of the attribute's value, see SGML documentation for a description of the meaning of the different attribute value types.
The deft field describes the kind of default value for this attribute, see SGML documentation for a description of the meaning of the different default value types.
The {\tt name} field gives the name of this attribute.
The valuestring} field gives the value of this attribute as a string (Char array). This is a union type because in a latter release we may want to introduce typed attribute values.
The next field points to another NSL_Attr structure for the next attribute defined on this start tag, or NULL if this is the last.
The following functions manipulate NSL_Attrs
- Table of Contents
- SetAttrValue — set value within attribute
- GetAttrValue — Get the string value of an NSL_attr.
- CopyAttr — fresh copy of an attribute
- FindAttr — search for an attribute by name in an attribute list
- FreeAttr — free the memory associated with a list of attribute-value pairs
SetAttrValue
Description
Set the value of an NSL_attr to a string. The return value is TRUE for success and FALSE for an error.
GetAttrValue
CopyAttr
Description
Copy an NSL_attr. This copies the whole linked list of NSL_Attrs pointed to by attr. It allocates memory from the memory pool associated with item.
Note: The item is new, motivated by considerations of thread safety.
FindAttr
Description
Search down the linked list of NSL_Attrs starting at attr to find one which has the given name
FreeAttr
XIX. Miscellaneous
- Table of Contents
- ParseInit — no longer documented
ParseInit
Notes
This was documented in LT XML 1.1, but shouldn't have been. It does some internal initialisation for the parser, and is indirectly called by NSLInit. As far as we can see the reason for documenting it was to permit use of the parser without the rest of the API. This need is now better met by direct use of RXP.